This repository provides training scripts for speech enhancement models. Currently, it supports fresh train or finetune for the following models:
| model name | sampling rate | Paper Link |
|---|---|---|
| FRCRN_SE_16K | 16000 | FRCRN (Paper, ICASSP 2022) |
| MossFormerGAN_SE_16K | 16000 | MossFormer2 Backbone + GAN (Paper, ICASSP 2024) |
| MossFormer2_SE_48K | 48000 | MossFormer2 Backbone + Masking (Paper, ICASSP 2024) |
- FRCRN_SE_16K
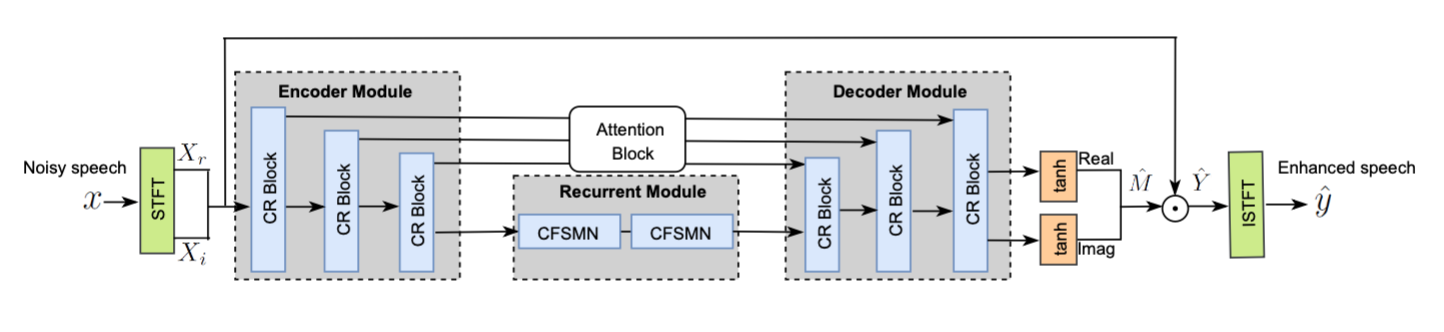
FRCRN uses a complex network for single-channel speech enhancement. It is a generalized method for enhancing speech in various noise environments. Our trained FRCRN model has won good performance in IEEE ICASSP 2022 DNS Challenge. Please check our paper.
The FRCRN model is developed based on a new framework of Convolutional Recurrent Encoder-Decoder (CRED), which is built on the Convolutional Encoder-Decoder (CED) architecture. CRED can significantly improve the performance of the convolution kernel by improving the limited receptive fields in the convolutions of CED using frequency recurrent layers. In addition, we introduce the Complex Feedforward Sequential Memory Network (CFSMN) to reduce the complexity of the recurrent network, and apply complex-valued network operations to realize the full complex deep model, which not only constructs long sequence speech more effectively, but also can enhance the amplitude and phase of speech at the same time.
- MossFormerGAN_SE_16K
MossFormerGAN is motivated from CMGAN and TF-GridNet. We use an extended MossFormer2 backbone (See below figure) to replace Conformer in CMGAN and add the Full-band Self-attention Modul proposed in TF-GridNet. The whole speech enhancemnt network is optimized by the adversarial training scheme as described in CMGAN. We extended the CNN network to an attention-based network for the discriminator. MossFormerGAN is trained for 16kHz speech enhancement.

- MossFormer2_SE_48K
MossFormer2_SE_48K is a full-band (48kHz) speech enhancement model. Full-band 48 kHz speech enhancement is becoming increasingly important due to advancements in communication platforms and high-quality media consumption. Several open-sourced github repos such as FullSubNet, DeepFilterNet, and resemble-enhance have released pre-trained models. We provide a more competitive MossFormer2_SE_48K model in our ClearVoice and the training and finetune scripts here.
MossFormer2_SE_48K uses the following model architecture. It uses noisy fbank as input to predict the Phase-Sensitive Mask (PSM). Then, the predicted mask is applied to the noisy STFT spectrogram. Finally, the estimated STFT spectrogram is converted back to waveform by IFFT. The main component is the MossFormer2 block which consists of a MossFormer module and a Recurrent model. The number of MossFormer2 blocks can be adjusted to deepen the network. We used 24 MossFormer2 blocks in MossFormer2_SE_48K.

We provided performance comparisons of our released models with the publically available models in ClearVoice page.
If you haven't created a Conda environment for ClearerVoice-Studio yet, follow steps 1 and 2. Otherwise, skip directly to step 3.
- Clone the Repository
git clone https://github.com/modelscope/ClearerVoice-Studio.git- Create Conda Environment
cd ClearerVoice-Studio
conda create -n ClearerVoice-Studio python=3.8
conda activate ClearerVoice-Studio
pip install -r requirements.txt- Prepare Dataset
If you don't have any training dataset to start with, we recommend you to download the VoiceBank-DEMAND dataset (link]. You may store the dataset anywhere. What you need to start the model training is to create two scp files as shown in data/tr_demand_28_spks_16k.scp and data/cv_demand_testset_16k.scp. data/tr_demand_28_spks_16k.scp contains the training data list and data/cv_demand_testset_16k.scp contains the testing data list.
Replace data/tr_demand_28_spks_16k.scp and data/cv_demand_testset_16k.scp with your new .scp files in config/train/*.yaml. Now it is ready to train the models.
- Start Training
bash train.shYou may need to set the correct network in train.sh and choose either a fresh training or a finetune process using:
network=MossFormer2_SE_48K #Train MossFormer2_SE_48K model
train_from_last_checkpoint=1 #Set 1 to start training from the last checkpoint if exists,
init_checkpoint_path=./ #Path to your initial model if starting fine-tuning; otherwise, set it to 'None'