ch. 3. Logistic Regression Classifier using gradient descent #147
Comments
Nowadays, they are indeed mostly used synonymously.
I was using the traditional "terminology" where the "error" is the difference between the label and the prediction.
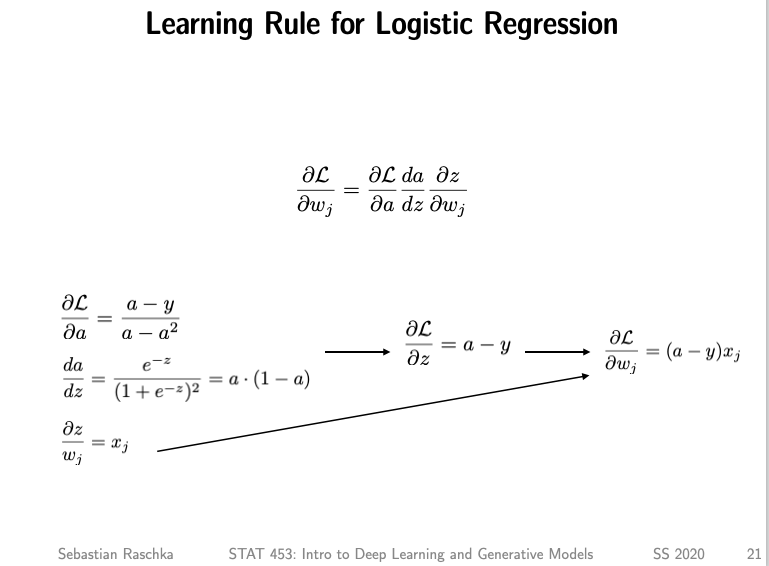
Good question, it's not very obvious from looking at it in this code, but that's because that's derivative of the loss (or cost) function. I have summarized it on the slide below:
Yeah, good point. You will have to update the weight update, too. So, instead of self.w_[1:] += self.eta * (X.T.dot(errors))it can be changed to self.w_[1:] += self.eta * (X.T.dot(errors) - self.l2_lambda * self.w_[1:]) |
|
Fantastic, that makes sense! thank you for clarifying. |
Thank you for writing this wonderful book. It has allowed me to recollect all my learnings from "The Introduction to Statistical Learning" book plus learn some practical insights.
That said, one of the examples has caused some confusion regarding how the cost or error (or loss) function is computed and then applied to calculate the weights. My understanding is that cost, loss or error functions are essentially one and the same but in this particular case they are likely used differently. Looking at the implementation of the logistic regression algorithm raises a few questions:
Can you share your thoughts?
The text was updated successfully, but these errors were encountered: