In recent years, tremendous amount of progress is being made in the field of 3D Machine Learning, which is an interdisciplinary field that fuses computer vision, computer graphics and machine learning. This repo is derived from my study notes and will be used as a place for triaging new research papers.
I'll use the following icons to differentiate 3D representations:
- 📷 Multi-view Images
- 👾 Volumetric
- 🎲 Point Cloud
- 💎 Polygonal Mesh
- 💊 Primitive-based
To find related papers and their relationships, check out Connected Papers, which provides a neat way to visualize the academic field in a graph representation.
To contribute to this Repo, you may add content through pull requests or open an issue to let me know.
⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐
We have also created a Slack workplace for people around the globe to ask questions, share knowledge and facilitate collaborations. Together, I'm sure we can advance this field as a collaborative effort. Join the community with this link.
⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐
- Courses
- Datasets
- 3D Pose Estimation
- Single Object Classification
- Multiple Objects Detection
- Scene/Object Semantic Segmentation
- 3D Geometry Synthesis/Reconstruction
- Texture/Material Analysis and Synthesis
- Style Learning and Transfer
- Scene Synthesis/Reconstruction
- Scene Understanding
Stanford CS231A: Computer Vision-From 3D Reconstruction to Recognition (Winter 2018)
UCSD CSE291-I00: Machine Learning for 3D Data (Winter 2018)
Stanford CS468: Machine Learning for 3D Data (Spring 2017)
MIT 6.838: Shape Analysis (Spring 2017)
Princeton COS 526: Advanced Computer Graphics (Fall 2010)
Princeton CS597: Geometric Modeling and Analysis (Fall 2003)
Paper Collection for 3D Understanding
CreativeAI: Deep Learning for Graphics
To see a survey of RGBD datasets, check out Michael Firman's collection as well as the associated paper, RGBD Datasets: Past, Present and Future. Point Cloud Library also has a good dataset catalogue.
Princeton Shape Benchmark (2003) [Link]
1,814 models collected from the web in .OFF format. Used to evaluating shape-based retrieval and analysis algorithms.
.jpeg)
Dataset for IKEA 3D models and aligned images (2013) [Link]
759 images and 219 models including Sketchup (skp) and Wavefront (obj) files, good for pose estimation.

Open Surfaces: A Richly Annotated Catalog of Surface Appearance (SIGGRAPH 2013) [Link]
OpenSurfaces is a large database of annotated surfaces created from real-world consumer photographs. Our annotation framework draws on crowdsourcing to segment surfaces from photos, and then annotate them with rich surface properties, including material, texture and contextual information.

PASCAL3D+ (2014) [Link]
12 categories, on average 3k+ objects per category, for 3D object detection and pose estimation.

ModelNet (2015) [Link]
127915 3D CAD models from 662 categories
ModelNet10: 4899 models from 10 categories
ModelNet40: 12311 models from 40 categories, all are uniformly orientated

ShapeNet (2015) [Link]
3Million+ models and 4K+ categories. A dataset that is large in scale, well organized and richly annotated.
ShapeNetCore [Link]: 51300 models for 55 categories.

A Large Dataset of Object Scans (2016) [Link]
10K scans in RGBD + reconstructed 3D models in .PLY format.

ObjectNet3D: A Large Scale Database for 3D Object Recognition (2016) [Link]
100 categories, 90,127 images, 201,888 objects in these images and 44,147 3D shapes.
Tasks: region proposal generation, 2D object detection, joint 2D detection and 3D object pose estimation, and image-based 3D shape retrieval

Thingi10K: A Dataset of 10,000 3D-Printing Models (2016) [Link]
10,000 models from featured “things” on thingiverse.com, suitable for testing 3D printing techniques such as structural analysis , shape optimization, or solid geometry operations.

ABC: A Big CAD Model Dataset For Geometric Deep Learning [Link][Paper]
This work introduce a dataset for geometric deep learning consisting of over 1 million individual (and high quality) geometric models, each associated with accurate ground truth information on the decomposition into patches, explicit sharp feature annotations, and analytic differential properties.

🎲 ScanObjectNN: A New Benchmark Dataset and Classification Model on Real-World Data (ICCV 2019) [Link]
This work introduce ScanObjectNN, a new real-world point cloud object dataset based on scanned indoor scene data. The comprehensive benchmark in this work shows that this dataset poses great challenges to existing point cloud classification techniques as objects from real-world scans are often cluttered with background and/or are partial due to occlusions. Three key open problems for point cloud object classification are identified, and a new point cloud classification neural network that achieves state-of-the-art performance on classifying objects with cluttered background is proposed.

VOCASET: Speech-4D Head Scan Dataset (2019( [Link][Paper]
VOCASET, is a 4D face dataset with about 29 minutes of 4D scans captured at 60 fps and synchronized audio. The dataset has 12 subjects and 480 sequences of about 3-4 seconds each with sentences chosen from an array of standard protocols that maximize phonetic diversity.

3D-FUTURE: 3D FUrniture shape with TextURE (2020( [Link]
VOCASET, contains 20,000+ clean and realistic synthetic scenes in 5,000+ diverse rooms, which include 10,000+ unique high quality 3D instances of furniture with high resolution informative textures developed by professional designers.

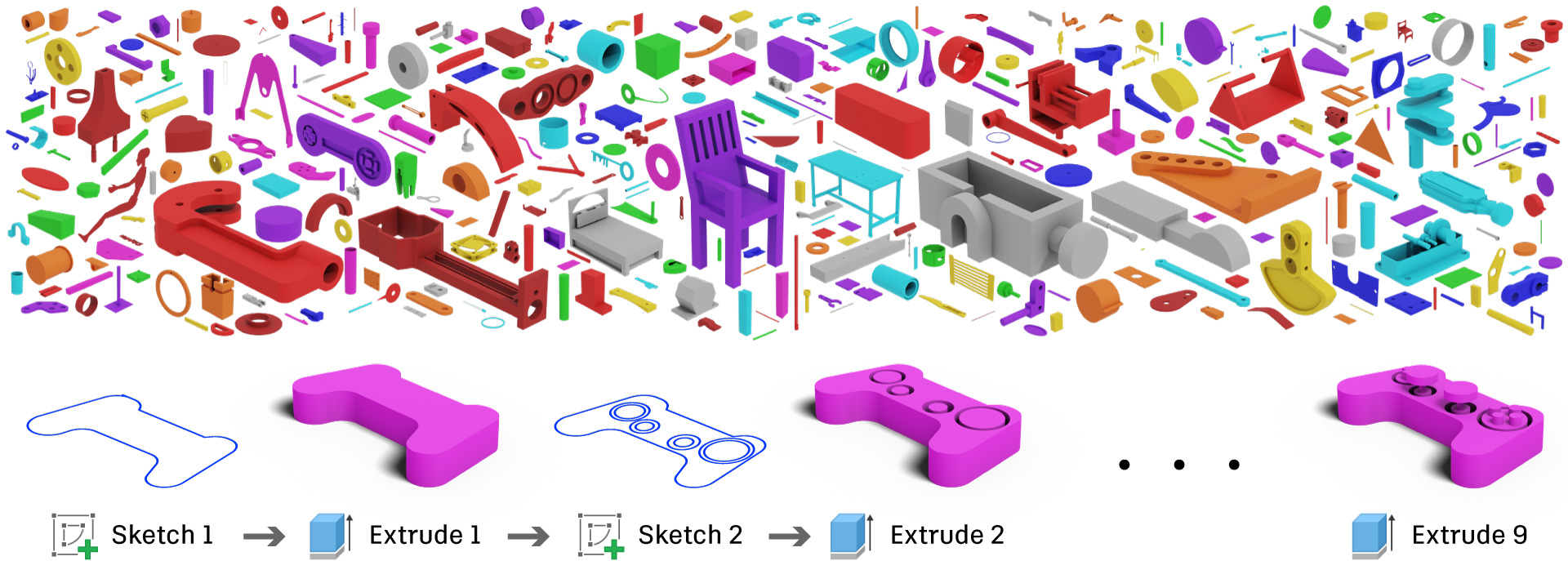
Fusion 360 Gallery Dataset (2020) [Link][Paper]
The Fusion 360 Gallery Dataset contains rich 2D and 3D geometry data derived from parametric CAD models. The Reconstruction Dataset provides sequential construction sequence information from a subset of simple 'sketch and extrude' designs. The Segmentation Dataset provides a segmentation of 3D models based on the CAD modeling operation, including B-Rep format, mesh, and point cloud.
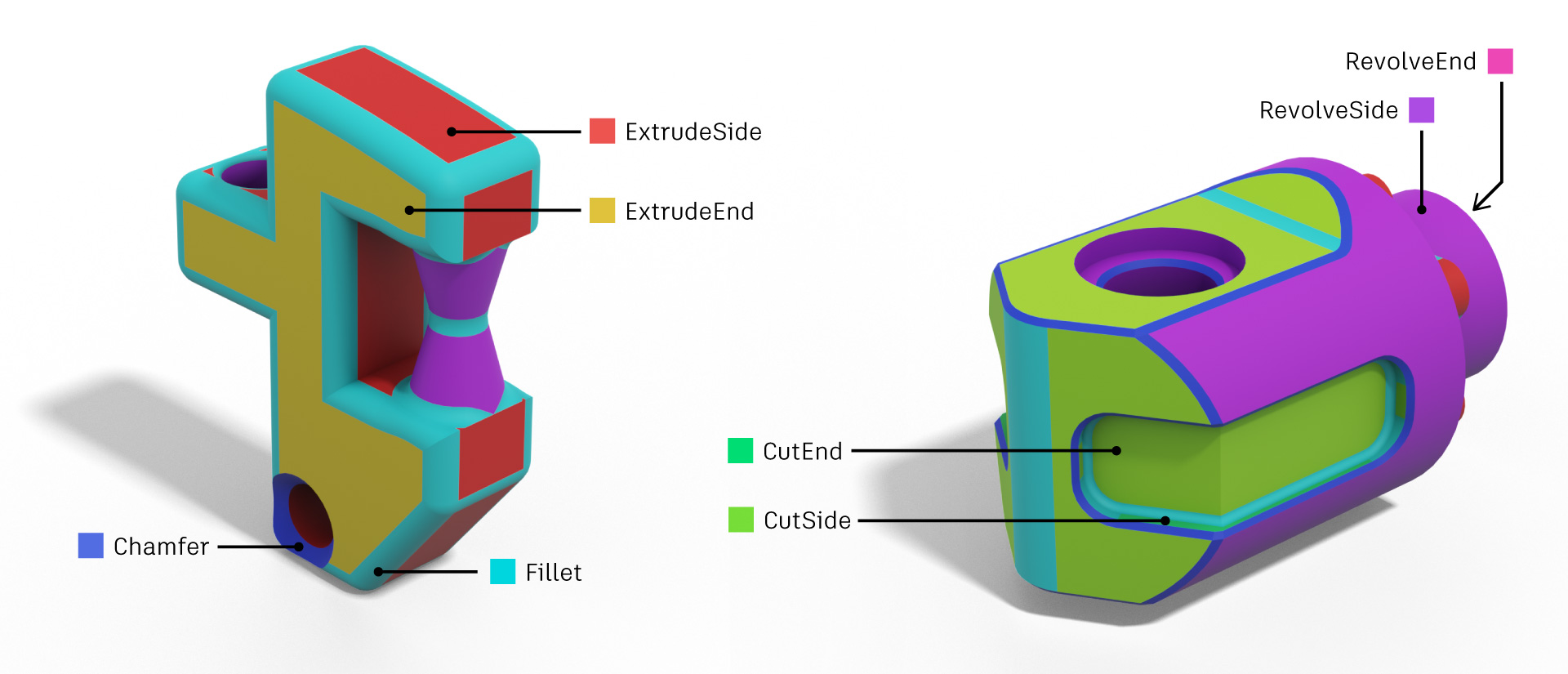
Combinatorial 3D Shape Dataset (2020) [Link][Paper]
Combinatorial 3D Shape Dataset is composed of 406 instances of 14 classes. Each object in our dataset is considered equivalent to a sequence of primitive placement. Compared to other 3D object datasets, our proposed dataset contains an assembling sequence of unit primitives. It implies that we can quickly obtain a sequential generation process that is a human assembling mechanism. Furthermore, we can sample valid random sequences from a given combinatorial shape after validating the sampled sequences. To sum up, the characteristics of our combinatorial 3D shape dataset are (i) combinatorial, (ii) sequential, (iii) decomposable, and (iv) manipulable.

NYU Depth Dataset V2 (2012) [Link]
1449 densely labeled pairs of aligned RGB and depth images from Kinect video sequences for a variety of indoor scenes.

SUNRGB-D 3D Object Detection Challenge [Link]
19 object categories for predicting a 3D bounding box in real world dimension
Training set: 10,355 RGB-D scene images, Testing set: 2860 RGB-D images

SceneNN (2016) [Link]
100+ indoor scene meshes with per-vertex and per-pixel annotation.

ScanNet (2017) [Link]
An RGB-D video dataset containing 2.5 million views in more than 1500 scans, annotated with 3D camera poses, surface reconstructions, and instance-level semantic segmentations.

Matterport3D: Learning from RGB-D Data in Indoor Environments (2017) [Link]
10,800 panoramic views (in both RGB and depth) from 194,400 RGB-D images of 90 building-scale scenes of private rooms. Instance-level semantic segmentations are provided for region (living room, kitchen) and object (sofa, TV) categories.

SUNCG: A Large 3D Model Repository for Indoor Scenes (2017) [Link]
The dataset contains over 45K different scenes with manually created realistic room and furniture layouts. All of the scenes are semantically annotated at the object level.

MINOS: Multimodal Indoor Simulator (2017) [Link]
MINOS is a simulator designed to support the development of multisensory models for goal-directed navigation in complex indoor environments. MINOS leverages large datasets of complex 3D environments and supports flexible configuration of multimodal sensor suites. MINOS supports SUNCG and Matterport3D scenes.

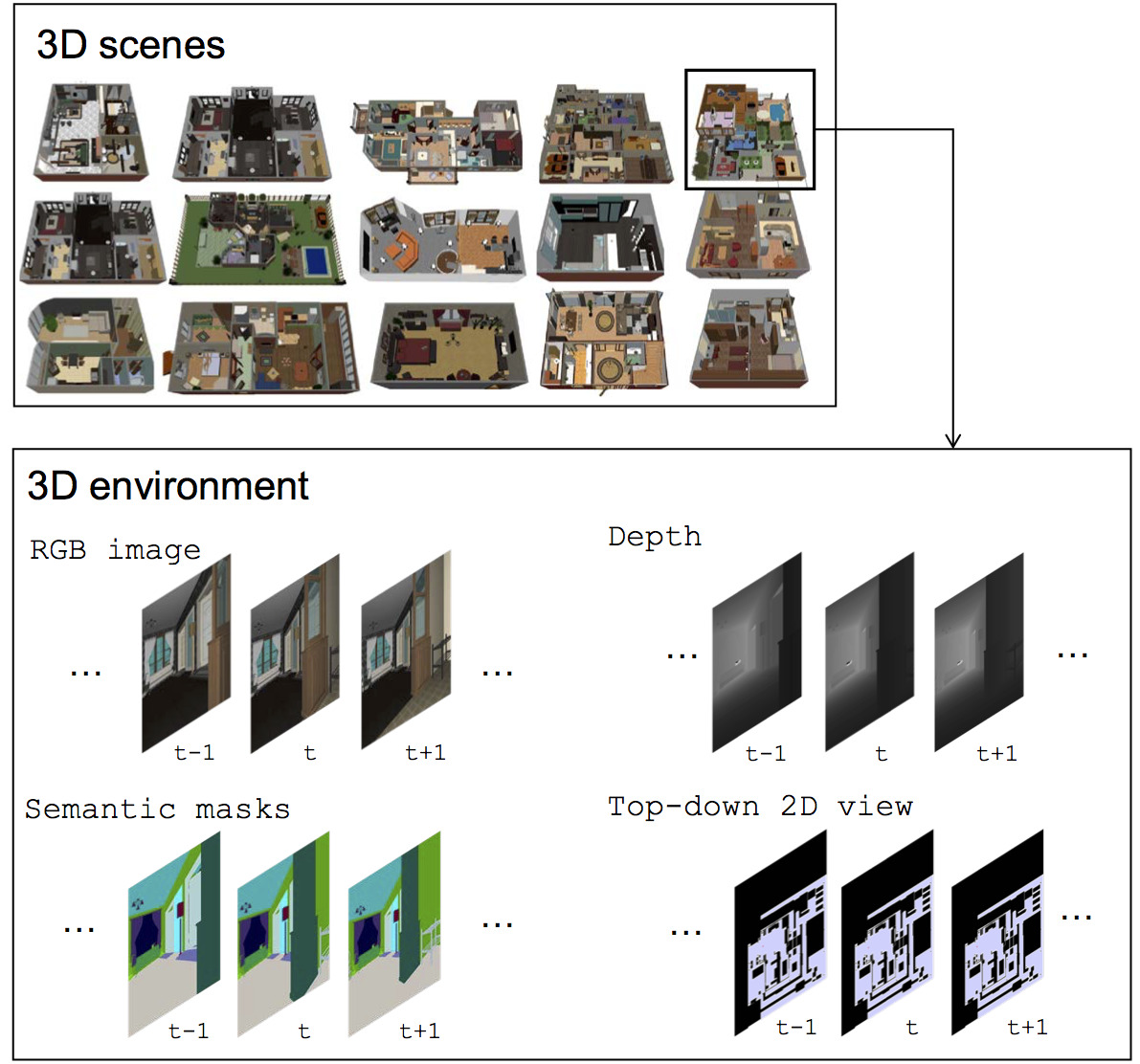
Facebook House3D: A Rich and Realistic 3D Environment (2017) [Link]
House3D is a virtual 3D environment which consists of 45K indoor scenes equipped with a diverse set of scene types, layouts and objects sourced from the SUNCG dataset. All 3D objects are fully annotated with category labels. Agents in the environment have access to observations of multiple modalities, including RGB images, depth, segmentation masks and top-down 2D map views.
HoME: a Household Multimodal Environment (2017) [Link]
HoME integrates over 45,000 diverse 3D house layouts based on the SUNCG dataset, a scale which may facilitate learning, generalization, and transfer. HoME is an open-source, OpenAI Gym-compatible platform extensible to tasks in reinforcement learning, language grounding, sound-based navigation, robotics, multi-agent learning.

AI2-THOR: Photorealistic Interactive Environments for AI Agents [Link]
AI2-THOR is a photo-realistic interactable framework for AI agents. There are a total 120 scenes in version 1.0 of the THOR environment covering four different room categories: kitchens, living rooms, bedrooms, and bathrooms. Each room has a number of actionable objects.

UnrealCV: Virtual Worlds for Computer Vision (2017) [Link][Paper]
An open source project to help computer vision researchers build virtual worlds using Unreal Engine 4.

Gibson Environment: Real-World Perception for Embodied Agents (2018 CVPR) [Link]
This platform provides RGB from 1000 point clouds, as well as multimodal sensor data: surface normal, depth, and for a fraction of the spaces, semantics object annotations. The environment is also RL ready with physics integrated. Using such datasets can further narrow down the discrepency between virtual environment and real world.
%20.jpeg)
InteriorNet: Mega-scale Multi-sensor Photo-realistic Indoor Scenes Dataset [Link]
System Overview: an end-to-end pipeline to render an RGB-D-inertial benchmark for large scale interior scene understanding and mapping. Our dataset contains 20M images created by pipeline: (A) We collect around 1 million CAD models provided by world-leading furniture manufacturers. These models have been used in the real-world production. (B) Based on those models, around 1,100 professional designers create around 22 million interior layouts. Most of such layouts have been used in real-world decorations. (C) For each layout, we generate a number of configurations to represent different random lightings and simulation of scene change over time in daily life. (D) We provide an interactive simulator (ViSim) to help for creating ground truth IMU, events, as well as monocular or stereo camera trajectories including hand-drawn, random walking and neural network based realistic trajectory. (E) All supported image sequences and ground truth.

Semantic3D[Link]
Large-Scale Point Cloud Classification Benchmark, which provides a large labelled 3D point cloud data set of natural scenes with over 4 billion points in total, and also covers a range of diverse urban scenes.

Structured3D: A Large Photo-realistic Dataset for Structured 3D Modeling [Link]

3D-FRONT: 3D Furnished Rooms with layOuts and semaNTics [Link]
Contains 10,000 houses (or apartments) and ~70,000 rooms with layout information.

3ThreeDWorld(TDW): A High-Fidelity, Multi-Modal Platform for Interactive Physical Simulation [Link]

Category-Specific Object Reconstruction from a Single Image (2014) [Paper]

Viewpoints and Keypoints (2015) [Paper]

Render for CNN: Viewpoint Estimation in Images Using CNNs Trained with Rendered 3D Model Views (2015 ICCV) [Paper]

PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization (2015) [Paper]

Modeling Uncertainty in Deep Learning for Camera Relocalization (2016) [Paper]

Robust camera pose estimation by viewpoint classification using deep learning (2016) [Paper]

Geometric loss functions for camera pose regression with deep learning (2017 CVPR) [Paper]

Generic 3D Representation via Pose Estimation and Matching (2017) [Paper]

3D Bounding Box Estimation Using Deep Learning and Geometry (2017) [Paper]

6-DoF Object Pose from Semantic Keypoints (2017) [Paper]

Relative Camera Pose Estimation Using Convolutional Neural Networks (2017) [Paper]

3DMatch: Learning Local Geometric Descriptors from RGB-D Reconstructions (2017) [Paper]

Single Image 3D Interpreter Network (2016) [Paper] [Code]

Multi-view Consistency as Supervisory Signal for Learning Shape and Pose Prediction (2018 CVPR) [Paper]

PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes (2018) [Paper]

Feature Mapping for Learning Fast and Accurate 3D Pose Inference from Synthetic Images (2018 CVPR) [Paper]
Pix3D: Dataset and Methods for Single-Image 3D Shape Modeling (2018 CVPR) [Paper]

3D Pose Estimation and 3D Model Retrieval for Objects in the Wild (2018 CVPR) [Paper]

Deep Object Pose Estimation for Semantic Robotic Grasping of Household Objects (2018) [Paper]

👾 3D ShapeNets: A Deep Representation for Volumetric Shapes (2015) [Paper]

👾 VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition (2015) [Paper] [Code]

📷 Multi-view Convolutional Neural Networks for 3D Shape Recognition (2015) [Paper]

📷 DeepPano: Deep Panoramic Representation for 3-D Shape Recognition (2015) [Paper]

👾📷 FusionNet: 3D Object Classification Using Multiple Data Representations (2016) [Paper]

👾📷 Volumetric and Multi-View CNNs for Object Classification on 3D Data (2016) [Paper] [Code]

👾 Generative and Discriminative Voxel Modeling with Convolutional Neural Networks (2016) [Paper] [Code]

💎 Geometric deep learning on graphs and manifolds using mixture model CNNs (2016) [Link]

👾 3D GAN: Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling (2016) [Paper] [Code]

👾 Generative and Discriminative Voxel Modeling with Convolutional Neural Networks (2017) [Paper]

👾 FPNN: Field Probing Neural Networks for 3D Data (2016) [Paper] [Code]

👾 OctNet: Learning Deep 3D Representations at High Resolutions (2017) [Paper] [Code]

👾 O-CNN: Octree-based Convolutional Neural Networks for 3D Shape Analysis (2017) [Paper] [Code]

👾 Orientation-boosted voxel nets for 3D object recognition (2017) [Paper] [Code]

🎲 PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation (2017) [Paper] [Code]

🎲 PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space (2017) [Paper] [Code]

📷 Feedback Networks (2017) [Paper] [Code]

🎲 Escape from Cells: Deep Kd-Networks for The Recognition of 3D Point Cloud Models (2017) [Paper]

🎲 Dynamic Graph CNN for Learning on Point Clouds (2018) [Paper]
🎲 PointCNN (2018) [Paper]

🎲📷 A Network Architecture for Point Cloud Classification via Automatic Depth Images Generation (2018 CVPR) [Paper]

🎲👾 PointGrid: A Deep Network for 3D Shape Understanding (CVPR 2018) [Paper] [Code]
.jpeg)
💎 MeshNet: Mesh Neural Network for 3D Shape Representation (AAAI 2019) [Paper] [Code]

🎲 SpiderCNN (2018) [Paper][Code]

🎲 PointConv (2018) [Paper][Code]

💎 MeshCNN (SIGGRAPH 2019) [Paper][Code]
🎲 SampleNet: Differentiable Point Cloud Sampling (CVPR 2020) [Paper] [Code]

Sliding Shapes for 3D Object Detection in Depth Images (2014) [Paper]

Object Detection in 3D Scenes Using CNNs in Multi-view Images (2016) [Paper]

Deep Sliding Shapes for Amodal 3D Object Detection in RGB-D Images (2016) [Paper] [Code]

Three-Dimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients (2016) [CVPR '16 Paper] [CVPR '18 Paper] [T-PAMI '19 Paper]

DeepContext: Context-Encoding Neural Pathways for 3D Holistic Scene Understanding (2016) [Paper]

SUN RGB-D: A RGB-D Scene Understanding Benchmark Suite (2017) [Paper]

VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection (2017) [Paper]

Frustum PointNets for 3D Object Detection from RGB-D Data (CVPR2018) [Paper]

A^2-Net: Molecular Structure Estimation from Cryo-EM Density Volumes (AAAI2019) [Paper]

Stereo R-CNN based 3D Object Detection for Autonomous Driving (CVPR2019) [Paper]

Deep Hough Voting for 3D Object Detection in Point Clouds (ICCV2019) [Paper] [code]

Learning 3D Mesh Segmentation and Labeling (2010) [Paper]

Unsupervised Co-Segmentation of a Set of Shapes via Descriptor-Space Spectral Clustering (2011) [Paper]

Single-View Reconstruction via Joint Analysis of Image and Shape Collections (2015) [Paper] [Code]

3D Shape Segmentation with Projective Convolutional Networks (2017) [Paper] [Code]

Learning Hierarchical Shape Segmentation and Labeling from Online Repositories (2017) [Paper]

👾 ScanNet (2017) [Paper] [Code]

🎲 PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation (2017) [Paper] [Code]
🎲 PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space (2017) [Paper] [Code]
🎲 3D Graph Neural Networks for RGBD Semantic Segmentation (2017) [Paper]

🎲 3DCNN-DQN-RNN: A Deep Reinforcement Learning Framework for Semantic Parsing of Large-scale 3D Point Clouds (2017) [Paper]

🎲👾 Semantic Segmentation of Indoor Point Clouds using Convolutional Neural Networks (2017) [Paper]

🎲👾 SEGCloud: Semantic Segmentation of 3D Point Clouds (2017) [Paper]

🎲👾 Large-Scale 3D Shape Reconstruction and Segmentation from ShapeNet Core55 (2017) [Paper]

🎲 Pointwise Convolutional Neural Networks (CVPR 2018) [Link]
We propose pointwise convolution that performs on-the-fly voxelization for learning local features of a point cloud.

🎲 Dynamic Graph CNN for Learning on Point Clouds (2018) [Paper]
🎲 PointCNN (2018) [Paper]
📷👾 3DMV: Joint 3D-Multi-View Prediction for 3D Semantic Scene Segmentation (2018) [Paper]

👾 ScanComplete: Large-Scale Scene Completion and Semantic Segmentation for 3D Scans (2018) [Paper]

🎲📷 SPLATNet: Sparse Lattice Networks for Point Cloud Processing (2018) [Paper]

🎲👾 PointGrid: A Deep Network for 3D Shape Understanding (CVPR 2018) [Paper] [Code]
🎲 PointConv (2018) [Paper][Code]
🎲 SpiderCNN (2018) [Paper][Code]
👾 3D-SIS: 3D Semantic Instance Segmentation of RGB-D Scans (CVPR 2019) [Paper][Code]

🎲 Real-time Progressive 3D Semantic Segmentation for Indoor Scenes (WACV 2019) [Link]
We propose an efficient yet robust technique for on-the-fly dense reconstruction and semantic segmentation of 3D indoor scenes. Our method is built atop an efficient super-voxel clustering method and a conditional random field with higher-order constraints from structural and object cues, enabling progressive dense semantic segmentation without any precomputation.

🎲 JSIS3D: Joint Semantic-Instance Segmentation of 3D Point Clouds (CVPR 2019) [Link]
We jointly address the problems of semantic and instance segmentation of 3D point clouds with a multi-task pointwise network that simultaneously performs two tasks: predicting the semantic classes of 3D points and embedding the points into high-dimensional vectors so that points of the same object instance are represented by similar embeddings. We then propose a multi-value conditional random field model to incorporate the semantic and instance labels and formulate the problem of semantic and instance segmentation as jointly optimising labels in the field model.

🎲 ShellNet: Efficient Point Cloud Convolutional Neural Networks using Concentric Shells Statistics (ICCV 2019) [Link]
We propose an efficient end-to-end permutation invariant convolution for point cloud deep learning. We use statistics from concentric spherical shells to define representative features and resolve the point order ambiguity, allowing traditional convolution to perform efficiently on such features.

🎲 Rotation Invariant Convolutions for 3D Point Clouds Deep Learning (3DV 2019) [Link]
We introduce a novel convolution operator for point clouds that achieves rotation invariance. Our core idea is to use low-level rotation invariant geometric features such as distances and angles to design a convolution operator for point cloud learning.

Parametric Morphable Model-based methods
A Morphable Model For The Synthesis Of 3D Faces (1999) [Paper][Code]

FLAME: Faces Learned with an Articulated Model and Expressions (2017) [Paper][Code (Chumpy)][Code (TF)] [Code (PyTorch)]
FLAME is a lightweight and expressive generic head model learned from over 33,000 of accurately aligned 3D scans. The model combines a linear identity shape space (trained from 3800 scans of human heads) with an articulated neck, jaw, and eyeballs, pose-dependent corrective blendshapes, and additional global expression blendshapes.
The code demonstrates how to 1) reconstruct textured 3D faces from images, 2) fit the model to 3D landmarks or registered 3D meshes, or 3) generate 3D face templates for speech-driven facial animation.

The Space of Human Body Shapes: Reconstruction and Parameterization from Range Scans (2003) [Paper]

SMPL-X: Expressive Body Capture: 3D Hands, Face, and Body from a Single Image (2019) [Paper][Video][Code]

PIFuHD: Multi-Level Pixel Aligned Implicit Function for High-Resolution 3D Human Digitization (CVPR 2020) [Paper][Video][Code]
ExPose: Monocular Expressive Body Regression through Body-Driven Attention (2020) [Paper][Video][Code]

Category-Specific Object Reconstruction from a Single Image (2014) [Paper]

🎲 DeformNet: Free-Form Deformation Network for 3D Shape Reconstruction from a Single Image (2017) [Paper]

💎 Mesh-based Autoencoders for Localized Deformation Component Analysis (2017) [Paper]

💎 Exploring Generative 3D Shapes Using Autoencoder Networks (Autodesk 2017) [Paper]

💎 Using Locally Corresponding CAD Models for Dense 3D Reconstructions from a Single Image (2017) [Paper]

💎 Compact Model Representation for 3D Reconstruction (2017) [Paper]

💎 Image2Mesh: A Learning Framework for Single Image 3D Reconstruction (2017) [Paper]

💎 Learning free-form deformations for 3D object reconstruction (2018) [Paper]

💎 Variational Autoencoders for Deforming 3D Mesh Models(2018 CVPR) [Paper]

💎 Lions and Tigers and Bears: Capturing Non-Rigid, 3D, Articulated Shape from Images (2018 CVPR) [Paper]

Part-based Template Learning methods
Modeling by Example (2004) [Paper]

Model Composition from Interchangeable Components (2007) [Paper]

Data-Driven Suggestions for Creativity Support in 3D Modeling (2010) [Paper]

Photo-Inspired Model-Driven 3D Object Modeling (2011) [Paper]

Probabilistic Reasoning for Assembly-Based 3D Modeling (2011) [Paper]

A Probabilistic Model for Component-Based Shape Synthesis (2012) [Paper]

Structure Recovery by Part Assembly (2012) [Paper]

Fit and Diverse: Set Evolution for Inspiring 3D Shape Galleries (2012) [Paper]

AttribIt: Content Creation with Semantic Attributes (2013) [Paper]

Learning Part-based Templates from Large Collections of 3D Shapes (2013) [Paper]

Topology-Varying 3D Shape Creation via Structural Blending (2014) [Paper]

Estimating Image Depth using Shape Collections (2014) [Paper]

Single-View Reconstruction via Joint Analysis of Image and Shape Collections (2015) [Paper]
Interchangeable Components for Hands-On Assembly Based Modeling (2016) [Paper]

Shape Completion from a Single RGBD Image (2016) [Paper]

Deep Learning Methods
📷 Learning to Generate Chairs, Tables and Cars with Convolutional Networks (2014) [Paper]

📷 Weakly-supervised Disentangling with Recurrent Transformations for 3D View Synthesis (2015, NIPS) [Paper]

🎲 Analysis and synthesis of 3D shape families via deep-learned generative models of surfaces (2015) [Paper]

📷 Weakly-supervised Disentangling with Recurrent Transformations for 3D View Synthesis (2015) [Paper] [Code]

📷 Multi-view 3D Models from Single Images with a Convolutional Network (2016) [Paper] [Code]

📷 View Synthesis by Appearance Flow (2016) [Paper] [Code]

👾 Voxlets: Structured Prediction of Unobserved Voxels From a Single Depth Image (2016) [Paper] [Code]

👾 3D-R2N2: 3D Recurrent Reconstruction Neural Network (2016) [Paper] [Code]

👾 Perspective Transformer Nets: Learning Single-View 3D Object Reconstruction without 3D Supervision (2016) [Paper]

👾 TL-Embedding Network: Learning a Predictable and Generative Vector Representation for Objects (2016) [Paper]

👾 3D GAN: Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling (2016) [Paper]
👾 3D Shape Induction from 2D Views of Multiple Objects (2016) [Paper]

📷 Unsupervised Learning of 3D Structure from Images (2016) [Paper]

👾 Generative and Discriminative Voxel Modeling with Convolutional Neural Networks (2016) [Paper] [Code]
📷 Multi-view Supervision for Single-view Reconstruction via Differentiable Ray Consistency (2017) [Paper]

📷 Synthesizing 3D Shapes via Modeling Multi-View Depth Maps and Silhouettes with Deep Generative Networks (2017) [Paper] [Code]

👾 Shape Completion using 3D-Encoder-Predictor CNNs and Shape Synthesis (2017) [Paper] [Code]

👾 Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs (2017) [Paper] [Code]

👾 Hierarchical Surface Prediction for 3D Object Reconstruction (2017) [Paper]

👾 OctNetFusion: Learning Depth Fusion from Data (2017) [Paper] [Code]

🎲 A Point Set Generation Network for 3D Object Reconstruction from a Single Image (2017) [Paper] [Code]
.jpeg)
🎲 Learning Representations and Generative Models for 3D Point Clouds (2017) [Paper] [Code]

🎲 Shape Generation using Spatially Partitioned Point Clouds (2017) [Paper]

🎲 PCPNET Learning Local Shape Properties from Raw Point Clouds (2017) [Paper]
.jpeg)
📷 Transformation-Grounded Image Generation Network for Novel 3D View Synthesis (2017) [Paper] [Code]

📷 Tag Disentangled Generative Adversarial Networks for Object Image Re-rendering (2017) [Paper]

📷 3D Shape Reconstruction from Sketches via Multi-view Convolutional Networks (2017) [Paper] [Code]

👾 Interactive 3D Modeling with a Generative Adversarial Network (2017) [Paper]

📷👾 Weakly supervised 3D Reconstruction with Adversarial Constraint (2017) [Paper] [Code]
.jpeg)
📷 SurfNet: Generating 3D shape surfaces using deep residual networks (2017) [Paper]

📷 Learning to Reconstruct Symmetric Shapes using Planar Parameterization of 3D Surface (2019) [Paper] [Code]

💊 GRASS: Generative Recursive Autoencoders for Shape Structures (SIGGRAPH 2017) [Paper] [Code] [code]

💊 3D-PRNN: Generating Shape Primitives with Recurrent Neural Networks (2017) [Paper][code]

💎 Neural 3D Mesh Renderer (2017) [Paper] [Code]

🎲👾 Large-Scale 3D Shape Reconstruction and Segmentation from ShapeNet Core55 (2017) [Paper]
👾 Pix2vox: Sketch-Based 3D Exploration with Stacked Generative Adversarial Networks (2017) [Code]

📷👾 What You Sketch Is What You Get: 3D Sketching using Multi-View Deep Volumetric Prediction (2017) [Paper]

📷👾 MarrNet: 3D Shape Reconstruction via 2.5D Sketches (2017) [Paper]

📷👾🎲 Learning a Multi-View Stereo Machine (2017 NIPS) [Paper]

👾 3DMatch: Learning Local Geometric Descriptors from RGB-D Reconstructions (2017) [Paper]
👾 Scaling CNNs for High Resolution Volumetric Reconstruction from a Single Image (2017) [Paper]

💊 ComplementMe: Weakly-Supervised Component Suggestions for 3D Modeling (2017) [Paper]

🎲 PU-Net: Point Cloud Upsampling Network (2018) [Paper] [Code]

📷👾 Multi-view Consistency as Supervisory Signal for Learning Shape and Pose Prediction (2018 CVPR) [Paper]
📷🎲 Object-Centric Photometric Bundle Adjustment with Deep Shape Prior (2018) [Paper]

📷🎲 Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction (2018 AAAI) [Paper]

💎 Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images (2018) [Paper]

💎 AtlasNet: A Papier-Mâché Approach to Learning 3D Surface Generation (2018 CVPR) [Paper] [Code]

👾💎 Deep Marching Cubes: Learning Explicit Surface Representations (2018 CVPR) [Paper]

👾 Im2Avatar: Colorful 3D Reconstruction from a Single Image (2018) [Paper]

💎 Learning Category-Specific Mesh Reconstruction from Image Collections (2018) [Paper]

💊 CSGNet: Neural Shape Parser for Constructive Solid Geometry (2018) [Paper]

👾 Text2Shape: Generating Shapes from Natural Language by Learning Joint Embeddings (2018) [Paper]

👾💎📷 Multi-View Silhouette and Depth Decomposition for High Resolution 3D Object Representation (2018) [Paper] [Code]


👾💎📷 Pixels, voxels, and views: A study of shape representations for single view 3D object shape prediction (2018 CVPR) [Paper]
![]()
📷🎲 Neural scene representation and rendering (2018) [Paper]

💊 Im2Struct: Recovering 3D Shape Structure from a Single RGB Image (2018 CVPR) [Paper]

🎲 FoldingNet: Point Cloud Auto-encoder via Deep Grid Deformation (2018 CVPR) [Paper]

📷👾 Pix3D: Dataset and Methods for Single-Image 3D Shape Modeling (2018 CVPR) [Paper]
.png)
💎 3D-RCNN: Instance-level 3D Object Reconstruction via Render-and-Compare (2018 CVPR) [Paper]
.jpeg)
👾 Matryoshka Networks: Predicting 3D Geometry via Nested Shape Layers (2018 CVPR) [Paper]
.jpeg)
💎 Deformable Shape Completion with Graph Convolutional Autoencoders (2018 CVPR) [Paper]

👾 Global-to-Local Generative Model for 3D Shapes (SIGGRAPH Asia 2018) [Paper][Code]

💎🎲👾 ALIGNet: Partial-Shape Agnostic Alignment via Unsupervised Learning (TOG 2018) [Paper] [Code]

🎲👾 PointGrid: A Deep Network for 3D Shape Understanding (CVPR 2018) [Paper] [Code]
🎲 GAL: Geometric Adversarial Loss for Single-View 3D-Object Reconstruction (2018) [Paper]

🎲 Visual Object Networks: Image Generation with Disentangled 3D Representation (2018) [Paper]
.jpeg)
👾 Learning to Infer and Execute 3D Shape Programs (2019)) [Paper]

👾 Learning to Infer and Execute 3D Shape Programs (2019)) [Paper]

💎 Learning View Priors for Single-view 3D Reconstruction (CVPR 2019) [Paper]

💎🎲 Learning Embedding of 3D models with Quadric Loss (BMVC 2019) [Paper] [Code]

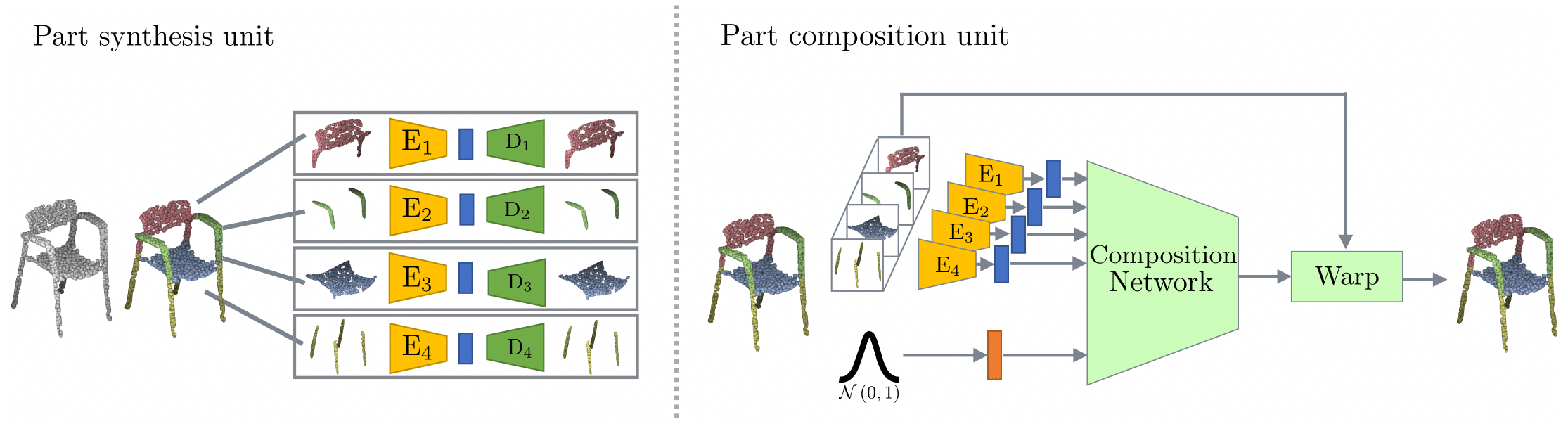
🎲 CompoNet: Learning to Generate the Unseen by Part Synthesis and Composition (ICCV 2019) [Paper][Code]
CoMA: Convolutional Mesh Autoencoders (2018) [Paper][Code (TF)][Code (PyTorch)][Code (PyTorch)]
CoMA is a versatile model that learns a non-linear representation of a face using spectral convolutions on a mesh surface. CoMA introduces mesh sampling operations that enable a hierarchical mesh representation that captures non-linear variations in shape and expression at multiple scales within the model.

RingNet: 3D Face Reconstruction from Single Images (2019) [Paper][Code]

VOCA: Voice Operated Character Animation (2019) [Paper][Video][Code]
VOCA is a simple and generic speech-driven facial animation framework that works across a range of identities. The codebase demonstrates how to synthesize realistic character animations given an arbitrary speech signal and a static character mesh.

💎 Learning to Predict 3D Objects with an Interpolation-based Differentiable Renderer [Paper][Site][Code]

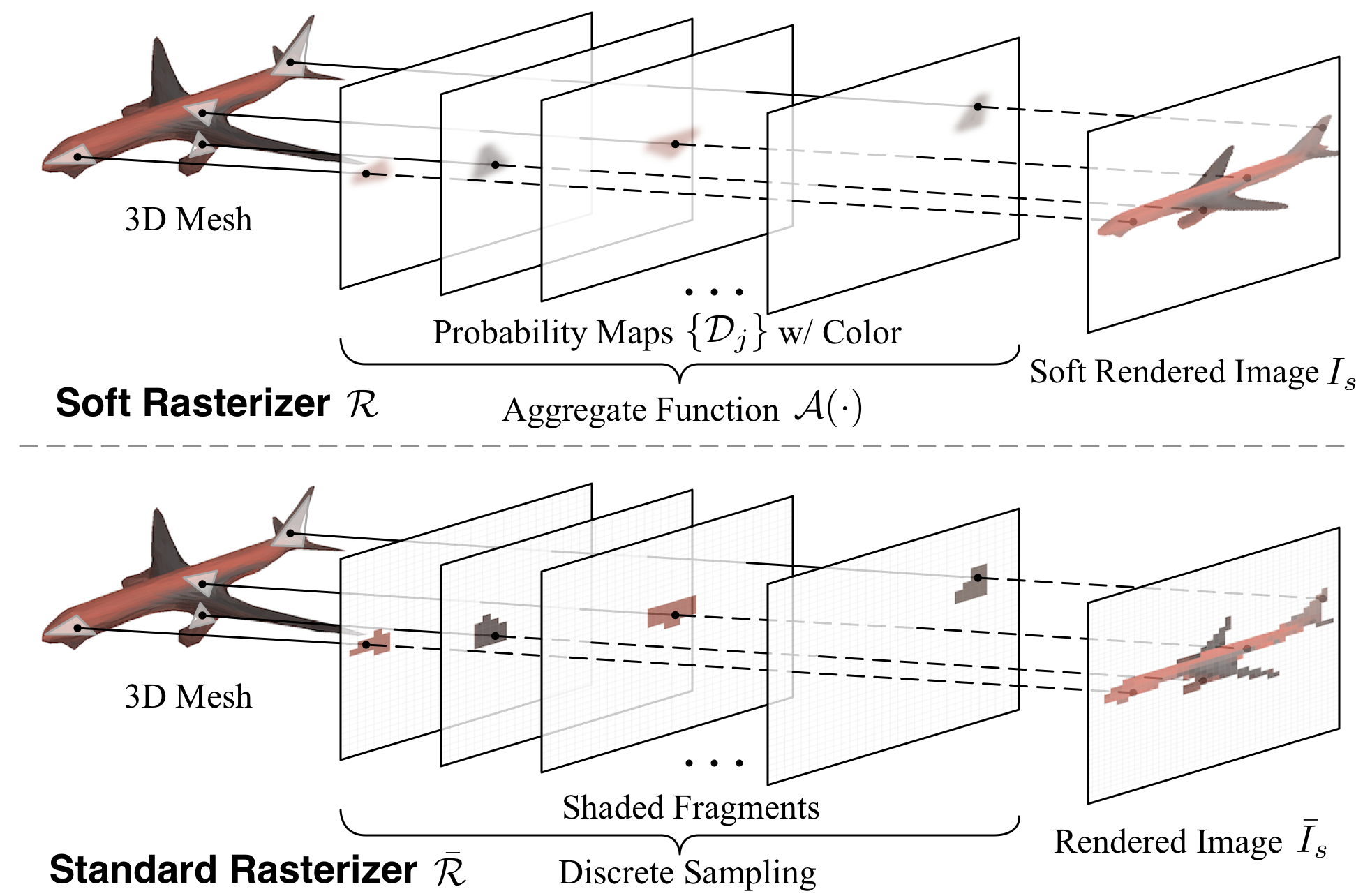
💎 Soft Rasterizer: A Differentiable Renderer for Image-based 3D Reasoning [Paper][Code]
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis [Project][Paper][Code]

💎🎲 GAMesh: Guided and Augmented Meshing for Deep Point Networks (3DV 2020) [Project] [Paper] [Code]

Texture Synthesis Using Convolutional Neural Networks (2015) [Paper]

Two-Shot SVBRDF Capture for Stationary Materials (SIGGRAPH 2015) [Paper]

Reflectance Modeling by Neural Texture Synthesis (2016) [Paper]

Modeling Surface Appearance from a Single Photograph using Self-augmented Convolutional Neural Networks (2017) [Paper]

High-Resolution Multi-Scale Neural Texture Synthesis (2017) [Paper]

Reflectance and Natural Illumination from Single Material Specular Objects Using Deep Learning (2017) [Paper]

Joint Material and Illumination Estimation from Photo Sets in the Wild (2017) [Paper]

JWhat Is Around The Camera? (2017) [Paper]

TextureGAN: Controlling Deep Image Synthesis with Texture Patches (2018 CVPR) [Paper]

Gaussian Material Synthesis (2018 SIGGRAPH) [Paper]

Non-stationary Texture Synthesis by Adversarial Expansion (2018 SIGGRAPH) [Paper]

Synthesized Texture Quality Assessment via Multi-scale Spatial and Statistical Texture Attributes of Image and Gradient Magnitude Coefficients (2018 CVPR) [Paper]

LIME: Live Intrinsic Material Estimation (2018 CVPR) [Paper]

Single-Image SVBRDF Capture with a Rendering-Aware Deep Network (2018) [Paper]

PhotoShape: Photorealistic Materials for Large-Scale Shape Collections (2018) [Paper]

Learning Material-Aware Local Descriptors for 3D Shapes (2018) [Paper]
.jpeg)
FrankenGAN: Guided Detail Synthesis for Building Mass Models using Style-Synchonized GANs (2018 SIGGRAPH Asia) [Paper]

Style-Content Separation by Anisotropic Part Scales (2010) [Paper]

Design Preserving Garment Transfer (2012) [Paper]

Analogy-Driven 3D Style Transfer (2014) [Paper]

Elements of Style: Learning Perceptual Shape Style Similarity (2015) [Paper] [Code]

Functionality Preserving Shape Style Transfer (2016) [Paper] [Code]
Unsupervised Texture Transfer from Images to Model Collections (2016) [Paper]

Learning Detail Transfer based on Geometric Features (2017) [Paper]

Co-Locating Style-Defining Elements on 3D Shapes (2017) [Paper]

Neural 3D Mesh Renderer (2017) [Paper] [Code]
Appearance Modeling via Proxy-to-Image Alignment (2018) [Paper]

💎 Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images (2018) [Paper]

Automatic Unpaired Shape Deformation Transfer (SIGGRAPH Asia 2018) [Paper]

Make It Home: Automatic Optimization of Furniture Arrangement (2011, SIGGRAPH) [Paper]

Interactive Furniture Layout Using Interior Design Guidelines (2011) [Paper]

Synthesizing Open Worlds with Constraints using Locally Annealed Reversible Jump MCMC (2012) [Paper]
.jpeg)
Example-based Synthesis of 3D Object Arrangements (2012 SIGGRAPH Asia) [Paper]

Sketch2Scene: Sketch-based Co-retrieval and Co-placement of 3D Models (2013) [Paper]

Action-Driven 3D Indoor Scene Evolution (2016) [Paper]

The Clutterpalette: An Interactive Tool for Detailing Indoor Scenes (2015) [Paper]

Image2Scene: Transforming Style of 3D Room (2015) [Paper]

Relationship Templates for Creating Scene Variations (2016) [Paper]

IM2CAD (2017) [Paper]

Predicting Complete 3D Models of Indoor Scenes (2017) [Paper]

Complete 3D Scene Parsing from Single RGBD Image (2017) [Paper]

Raster-to-Vector: Revisiting Floorplan Transformation (2017, ICCV) [Paper] [Code]

Fully Convolutional Refined Auto-Encoding Generative Adversarial Networks for 3D Multi Object Scenes (2017) [Blog]

Adaptive Synthesis of Indoor Scenes via Activity-Associated Object Relation Graphs (2017 SIGGRAPH Asia) [Paper]

Automated Interior Design Using a Genetic Algorithm (2017) [Paper]

SceneSuggest: Context-driven 3D Scene Design (2017) [Paper]
.png)
A fully end-to-end deep learning approach for real-time simultaneous 3D reconstruction and material recognition (2017) [Paper]
.png)
Human-centric Indoor Scene Synthesis Using Stochastic Grammar (2018, CVPR)[Paper] [Supplementary] [Code]

📷🎲 FloorNet: A Unified Framework for Floorplan Reconstruction from 3D Scans (2018) [Paper] [Code]

👾 ScanComplete: Large-Scale Scene Completion and Semantic Segmentation for 3D Scans (2018) [Paper]

Deep Convolutional Priors for Indoor Scene Synthesis (2018) [Paper]

📷 Fast and Flexible Indoor scene synthesis via Deep Convolutional Generative Models (2018) [Paper] [Code]

Configurable 3D Scene Synthesis and 2D Image Rendering with Per-Pixel Ground Truth using Stochastic Grammars (2018) [Paper]

Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image (ECCV 2018) [Paper]

Language-Driven Synthesis of 3D Scenes from Scene Databases (SIGGRAPH Asia 2018) [Paper]

Deep Generative Modeling for Scene Synthesis via Hybrid Representations (2018) [Paper]
.jpeg)
GRAINS: Generative Recursive Autoencoders for INdoor Scenes (2018) [Paper]

SEETHROUGH: Finding Objects in Heavily Occluded Indoor Scene Images (2018) [Paper]

👾 Scan2CAD: Learning CAD Model Alignment in RGB-D Scans (CVPR 2019) [Paper] [Code]

💎 Scan2Mesh: From Unstructured Range Scans to 3D Meshes (CVPR 2019) [Paper]

👾 3D-SIC: 3D Semantic Instance Completion for RGB-D Scans (arXiv 2019) [Paper]

👾 End-to-End CAD Model Retrieval and 9DoF Alignment in 3D Scans (arXiv 2019) [Paper]

A Survey of 3D Indoor Scene Synthesis (2020) [Paper]

💊 📷 PlanIT: Planning and Instantiating Indoor Scenes with Relation Graph and Spatial Prior Networks (2019) [Paper] [Code]

👾 Feature-metric Registration: A Fast Semi-Supervised Approach for Robust Point Cloud Registration without Correspondences (CVPR 2020) [Paper][Code]

💊 Human-centric metrics for indoor scene assessment and synthesis (2020) [Paper]

SceneCAD: Predicting Object Alignments and Layouts in RGB-D Scans (2020) [Paper]

Scene Understanding (Another more detailed repository)
Recovering the Spatial Layout of Cluttered Rooms (2009) [Paper]

Characterizing Structural Relationships in Scenes Using Graph Kernels (2011 SIGGRAPH) [Paper]

Understanding Indoor Scenes Using 3D Geometric Phrases (2013) [Paper]

Organizing Heterogeneous Scene Collections through Contextual Focal Points (2014 SIGGRAPH) [Paper]

SceneGrok: Inferring Action Maps in 3D Environments (2014, SIGGRAPH) [Paper]

PanoContext: A Whole-room 3D Context Model for Panoramic Scene Understanding (2014) [Paper]

Learning Informative Edge Maps for Indoor Scene Layout Prediction (2015) [Paper]

Rent3D: Floor-Plan Priors for Monocular Layout Estimation (2015) [Paper]

A Coarse-to-Fine Indoor Layout Estimation (CFILE) Method (2016) [Paper]
%20Method%20(2016).png)
DeLay: Robust Spatial Layout Estimation for Cluttered Indoor Scenes (2016) [Paper]

3D Semantic Parsing of Large-Scale Indoor Spaces (2016) [Paper] [Code]

Single Image 3D Interpreter Network (2016) [Paper] [Code]
Deep Multi-Modal Image Correspondence Learning (2016) [Paper]

Physically-Based Rendering for Indoor Scene Understanding Using Convolutional Neural Networks (2017) [Paper] [Code] [Code] [Code] [Code]

RoomNet: End-to-End Room Layout Estimation (2017) [Paper]

SUN RGB-D: A RGB-D Scene Understanding Benchmark Suite (2017) [Paper]
Semantic Scene Completion from a Single Depth Image (2017) [Paper] [Code]

Factoring Shape, Pose, and Layout from the 2D Image of a 3D Scene (2018 CVPR) [Paper] [Code]

LayoutNet: Reconstructing the 3D Room Layout from a Single RGB Image (2018 CVPR) [Paper] [Code]

PlaneNet: Piece-wise Planar Reconstruction from a Single RGB Image (2018 CVPR) [Paper] [Code]

Cross-Domain Self-supervised Multi-task Feature Learning using Synthetic Imagery (2018 CVPR) [Paper]

Pano2CAD: Room Layout From A Single Panorama Image (2018 CVPR) [Paper]

Automatic 3D Indoor Scene Modeling from Single Panorama (2018 CVPR) [Paper]
.jpeg)
Single-Image Piece-wise Planar 3D Reconstruction via Associative Embedding (2019 CVPR) [Paper] [Code]

3D-Aware Scene Manipulation via Inverse Graphics (NeurIPS 2018) [Paper] [Code]

💎 3D Scene Reconstruction with Multi-layer Depth and Epipolar Transformers (ICCV 2019) [Paper]


PerspectiveNet: 3D Object Detection from a Single RGB Image via Perspective Points (NIPS 2019) [Paper]

Holistic++ Scene Understanding: Single-view 3D Holistic Scene Parsing and Human Pose Estimation with Human-Object Interaction and Physical Commonsense (ICCV 2019) [Paper & Code]
