Basic implementation of ControllerManager RNN from Progressive Neural Architecture Search.
- Uses tf.keras to define and train children / generated networks, which are found via sequential model-based optimization in Tensorflow, ranked by the Controller RNN.
- Define a state space by using
StateSpace, a manager which maintains input states and handles communication between the ControllerManager RNN and the user. ControllerManagermanages the training and evaluation of the Controller RNNNetworkManagerhandles the training and reward computation of the children models
At a high level : For full training details, please see train.py.
# construct a state space (the default operators are from the paper)
state_space = StateSpace(B, # B = number of blocks in each cell
operators=None # whether to use custom operators or the default ones from the paper
input_lookback_depth=0, # limit number of combined inputs from previous cell
input_lookforward_depth=0, # limit number of combined inputs in same cell
)
# create the managers
controller = ControllerManager(state_space, B, K) # K = number of children networks to train after initial step
manager = NetworkManager(dataset, epochs=max_epochs, batchsize=batchsize)
# For `B` number of trials
actions = controller.get_actions(K) # get all the children model to train in this trial
For each `child` in action
store reward = manager.get_reward(child) in `rewards` list
encoder.train(rewards) # train encoder RNN with a surrogate loss function
encoder.update() # build next set of children to train in next trial, and sort themOnce the RNN Controller has been trained above the above approach, we can then score all possible model combinations.
This might take a little while due to exponentially growing number of model configurations. This scoring procedure can be done
simply in score_architectures.py.
score_architectures.py has a similar setup to the train.py script, but you will notice that B parameter is larger (5) as
compare to the B parameter in train.py (3). Any number of B can be provided, which will increase the maximum width of the Cells generated.
In addition, if the search space is small enough, we can pass K (the maximum number of child models we want to compute) to be None. In doing so, all possible child models will be produced and scored by the Controller RNN.
Note: There is an additional parameter INPUT_B. This is the B parameter with which the RNN was trained. Without this,
the Controller RNN cannot know the size of the Input Embedding to create, and defaults to the current B. This in turn causes an issue when loading the weights (as the original embedding would have dimensions [B, EMBEDDING_DIM].
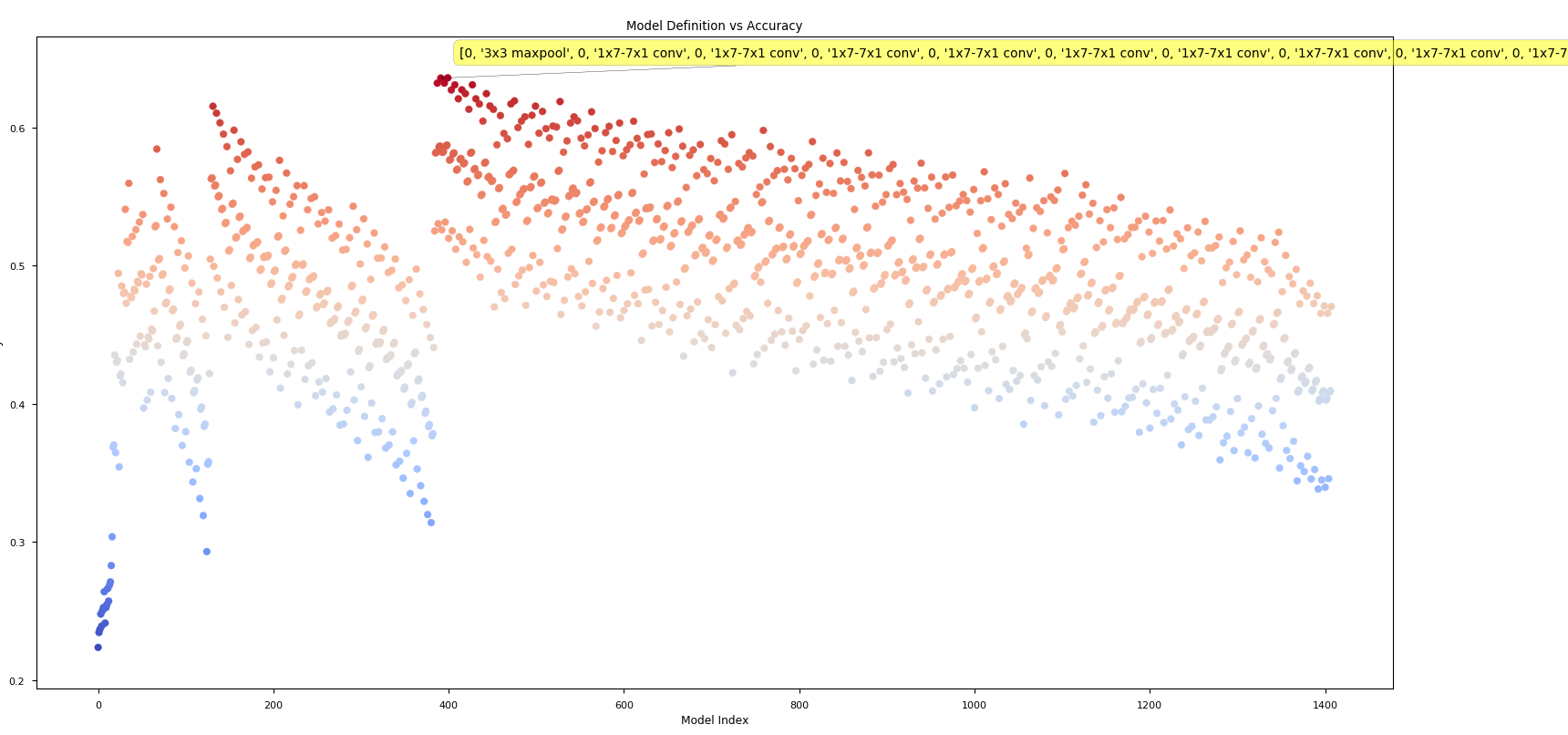
python score_architectures.pyFinally, we can visualize the results obtained by the Controller RNN and scored by the score_architecture.py script.
We do so by using the rank_architectures.py script, which accepts an argument -f. -f is a path(s) to the csv files that you want to rank and visualize.
Another argument is -sort, which will sort all the possible model combinations according to their predicted scores prior to plotting them. In doing so, if you have mplcursors setup, you can quickly glance at the top performing model architectures and their predicted scores.
There are many ways of calling this script :
- When you want to just visualize the history of the training procedure : Call it without any arguments.
python rank_architectures.py # optional -sort- When you want to visualize a specific
scorefile (to see the Controller RNN's predictions or actual evaluated model scores from training. These score files correspond to theBparameter in the paper, i.e. the width of the Cell generated.
python rank_architectures.py -f score_2.csv
# Here we assume we want to rank the `score_2.csv` file.- When you want to visualize multiple
scorefiles at once: pass them one after another. Note: The file names are sorted before display, so it will always show you scores in ascending order.
python rank_architectures.py -f score_5.csv score_3.csv score_2.csv- When you want to visualize all score files at once: Pass the file name as
score_*.csv. It uses glob internally, so all of its semantics will work here as well.
python rank_architectures.py -f scores_*.csv- When you want to visualize not just the scored files, but also the training history - i.e. visualize everything at once: Simply pass * to the
-fargument.
python rank_architectures.py -f *.csvThis is a very limited project.
- It is not a faithful re-implementation of the original paper. There are several small details not incorporated (like bias initialization, actually using the Hc-2 - Hcb-1 values etc)
- It doesnt have support for skip connections via 'anchor points' etc. (though it may not be that hard to implement it as a special state)
- Learning rate, number of epochs to train per B_i, regularization strength etc are all random values (which make somewhat sense to me)
- Single GPU model only. There would need to be a lot of modifications to this for multi GPU training (and I have just 1)
I tried a toy CNN model with 2 CNN cells the a custom search space, train for just 5 epoch of training on CIFAR-10.
All models configuration strings can be ranked using rank_architectures.py script to parse train_history.csv, or you can use
score_architectures.py to pseudo-score all combinations of models for all values of B, and then pass these onto rank_architectures.py to approximate the scores that they would obtain.
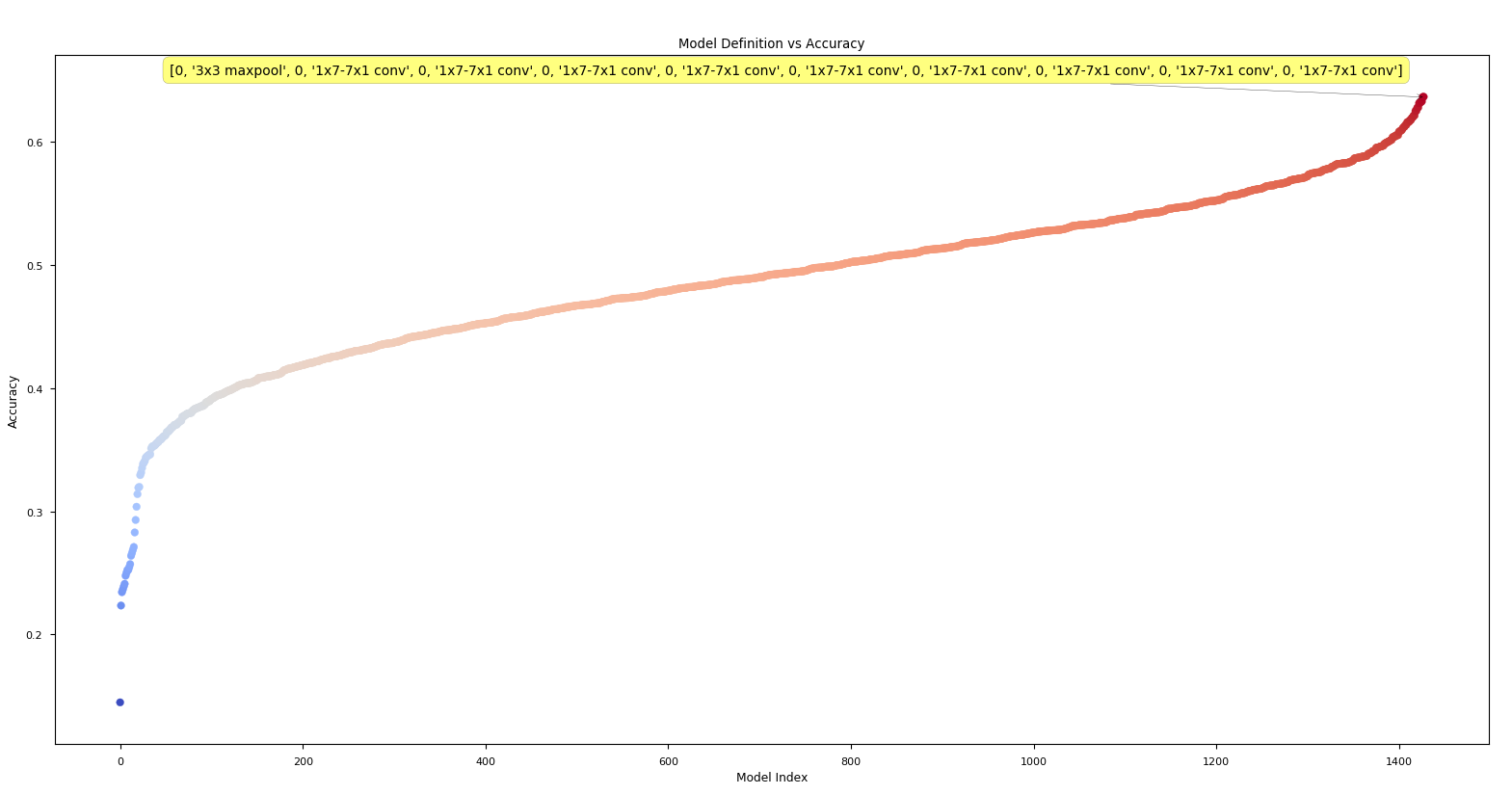
After sorting using the -sort argument in rank_architectures.py, we get the following of the same data as above.
- Tensorflow-gpu >= 1.12
- Scikit-learn (most recent available from pip)
- (Optional) matplotlib - to visualize using
rank_architectures.py - (Optional) mplcursors - to have annotated models when using
rank_architectures.py.
Code somewhat inspired by wallarm/nascell-automl