
AWS公用運算部門資深副總裁Peter DeSantis在今年年會首場主題演講中,揭露全託管AI平臺Amazon Bedrock的AI推論加速新功能預覽版。
攝影/王若樸
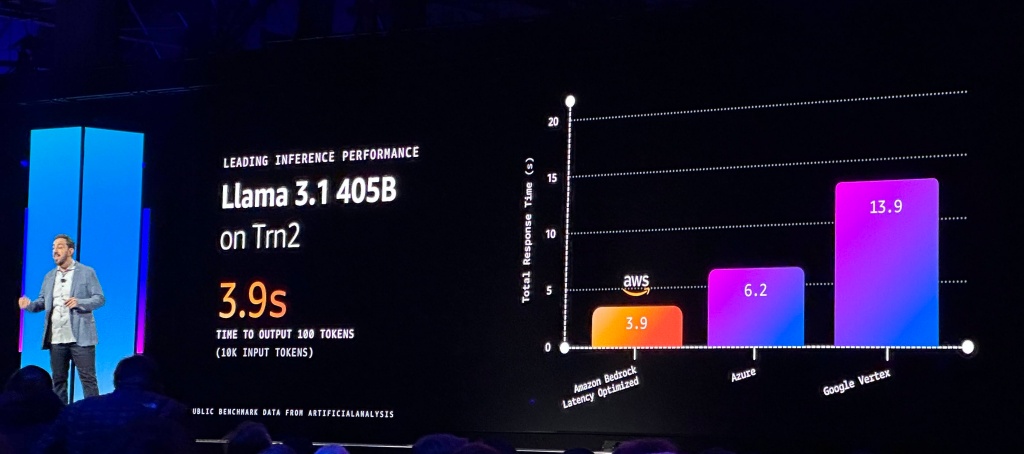
AWS re:Invent 2024技術年會於美西時間12月1日展開,其公用運算部門(Utility Computing)資深副總裁Peter DeSantis在晚間首場主題演講中,揭露全託管AI平臺Amazon Bedrock的AI推論加速新功能,主打降低延遲、提高效能,比如使用自家AI加速晶片Trainium 2驅動的Trn2執行個體執行Llama 3.1 405B模型推論,只需3.9秒就能處理1萬個Token的輸入值、產出100個Token,號稱比Google的13.9秒、微軟的6.2秒還要快。
不只Llama 3.1模型可加速,AI新創Anthropic共同創辦人暨運算長Tom Brown也現身說法,他們與AWS聯手設計Bedrock推論加速功能,能將Anthropic最新模型Claude 3.5 Haiku的推論時間加速60%,比其他任何平臺都還要快,即日起使用者即可透過API使用該功能。他也揭露,接下來將以數十萬顆Trainium 2訓練下一代Claude模型。
瞄準大語言模型需求,優化硬體打造預覽版Bedrock AI推論低延遲功能
進一步來說,AWS Bedrock是一款無伺服器的全託管AI平臺,使用者可透過API,存取Amazon自家和Meta、Anthropic或Stability AI等第三方基礎模型,來滿足業務需求。
Bedrock加速AI推論的關鍵,離不開硬體優化。在去年re:Invent大會中,AWS揭露自研AI加速晶片Trainium 2和Arm架構的Graviton 4處理器,現在還進一步發展出Trainium 2 UltraServer主機,包括了2個機櫃、4臺伺服器和64個以NeronLink高速連接的Trainium 2加速器,來提供單一高效能執行個體。(如下圖)

DeSantis補充,這臺Trainium 2 UltraServer能分別提供高達83.2 pflops和332.8 pflops的密集與稀疏運算效能,且具6TB的高頻寬記憶體(HBM),並在現場展示。(如下圖)

他還表示,這臺主機適合用來訓練兆級參數的大模型。
除了訓練需要強大算力,大模型的推論也需要強大算力支援,尤其目前出現越來越多仰賴多AI代理的工作流程,需要更快產出結果。
於是,在AWS的硬體優勢上,他們今年推出Bedrock AI推論低延遲功能(預覽版),能加速Llama 3.1 70B和405B等2種參數模型。他們測試,使用自家Trainium 2加速晶片執行405B參數的Llama 3.1模型推論,只需3.9秒就能對1萬個Token的輸入值,產出100個Token,號稱比Google的13.9秒、微軟的6.2秒還要快。(如下圖)
Claude 3.5 Haiku模型也加速推論,Anthropic還要用數十萬顆Trainium 2訓練新模型
不只是Llama模型,Anthropic也與AWS聯手開發推論加速功能,將Claude 3.5 Haiku小模型的推論時間加快了60%,「比其他任何平臺都還要快,」Tom Brown說。
他說明,要加速模型推論,不只是硬體規格要夠好,關鍵是主機中的收縮陣列(Systolic Arrays)要時時發揮作用。也就是說,收縮陣列要能持續依序接收模型輸入值,而不是卡住、得等待輸入值從記憶體或其他地方送進來,「就好比玩俄羅斯方塊一樣,方塊結合得越緊密就越有效率、成本也越低,」他比喻。
在與AWS解決這個問題的過程中,Anthropic發現,Trainium 2晶片的設計,非常適合執行低階程式語言,而且還能記錄系統中每條指令的執行時間。這意味著,開發者可以清楚知道,收縮陣列何時工作、何時卡住,以及為何卡住,讓核心(Kernel)程式的開發更快更簡單。
也因為Trainium 2晶片的這個優點,Tom Brown更透露,他們新一代的Claude模型,將用包含數十萬個Trainium 2晶片的Project Rainer來訓練,「這個叢集規模是我們所使用過的5倍之大。」這意味著,Anthropic的開發速度將更快,而Claude模型使用者,則能以更便宜的價格使用更聰明的模型,甚至是AI代理,來執行更重要的專案。

熱門新聞


2024-12-03
2024-11-29

2024-12-02

2024-12-02

2024-12-03
和日本大型電信業者KDDI宣布一項三年三階段生成式AI計畫,第一階段是要運用MUFG的數據打造專屬金融領域的LLM,預計今年完工。第二階段是要創造更多金融領域的應用,預計在明年實現。最後第三階段,則是要將這個金融領域的LLM發展為對外服務,計畫在2026年向金融業者推出金融LLM模型服務。")