-
GBDT说明
GBDT是Gradient Boosting Decison Tree的简称,其中Gradient是梯度,是这个方法的核心;Boosting是提升,是这个方法的框架;Decision Tree是决策树,是实现这个方法用到的模型。
GBDT可以解决回归问题,经过一些处理也可以解决分类(二类、多类)问题,但是用到的树都是回归树,这一点需要牢记。
首先通过简单的回归例子说明一下提升(Boosting)树:
举个例子,如果样本1的输出真实值为10,树T1针对样本1的预测值为18, 然后我们让树T2去拟合样本1的值为10-18=-8(残差)。如果树T2的输出值为-10, 我们再让树T3去拟合-8-(-10)=2(残差),结果树T3的预测值为1。 如果到此迭代结束,在最终对样本1的预测值为:18+(-10)+1=9。到这里,提升回归树的流程就大致清楚了。也就是通过多轮迭代,每轮迭代产生一个弱模型,每个模型都是在上一个模型的残差基础上进行训练的,最后将所有树的结果求和得出最终的结果。
GBDT就是在提升树的基础上,利用了梯度提升的方法,也就是用损失函数的负梯度在当前模型下的值来作为提升树中残差的近似值。对于GBDT用于回归问题而言,如果损失函数定义为MSE,则其负梯度就是残差。因此残差是损失函数负梯度的一种特殊情况。负梯度是残差这种思想的一般化。残差只可以用于回归问题,但是这种负梯度的思想也可用于分类问题。
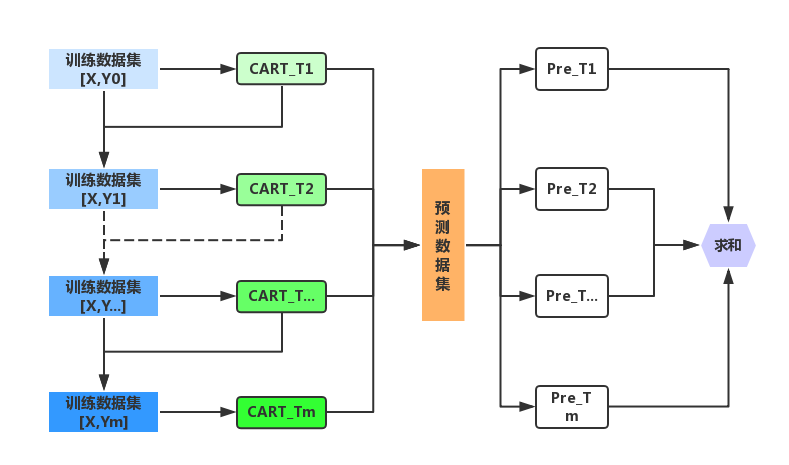
- GBDT流程图
-
GBDT步骤
-
回归问题
-
训练数据集
Y0为输出值序列,X0为输入的向量集合。
-
定义损失函数
-
MSE(GBDT回归所用)
-
绝对损失
-
Huber损失
它是MSE和绝对损失的组合形式,对于远离中心的异常点,采用绝对损失,其他的点采用MSE。
这个界限一般用分位数点度量。公式如下
-
-
初始化:针对数据集Data0,建立第一个CART回归树T0
CART回归树T0,说是树,其实就只包括一个叶子节点。
这个树的输出值就是使得损失函数值最小的数r,该树对于训练数据集的序列定义为Y_T0,
其实这个序列的元素全是r:
当前模型为F_0(x) = Y_T0
-
计算损失函数梯度
下面分别给出三种损失函数的负梯度在当前模型Y_T0下的值:
-
MSE
-
绝对损失
-
Huber损失
-
-
生成新的数据集Data1
-
建立CART回归树T1
针对新生成的数据集Data1,在建立CART回归树T1。
回归树T1建立完成后,每个叶子节点的输出值不再设定为平均值,
而是利用和初始化时相同的方法,对每一个叶子节点,
计算使得下式具有最小值的值作为该叶子节点的输出值:
下面以叶子节点h为例。
其中Y0_T1_h 表示树T1的叶子节点h中包含的样本的真实输出值,
c_T1_h为树T1的叶子节点h的最佳的输出值。训练数据集总的输出定义为c_T1
上述函数中前面的项是样本的真实输出值,这一点是不变的。
后面的项就是目前所有模型的集成值。
当前模型为F_1(x) = Y_T0 + c_T1
-
迭代
计算损失函数的负梯度在当前模型F_1(x)下的值,然后更新训练数据集的输出值,
然后再建立回归树,再计算每个叶子节点的最佳输出,
然后得到当前模型F_2(X),以此迭代,直到满足条件结束。
-
结果集成
假设对应m个弱模型的预测的结果分别为Pre_1, Pre_2,……,Pre_m, 将所有回归树的结果相加,
即为最终的结果,如下公式。
为了防止过拟合,可添加正则化的环节,
,a为正则化因子。
-
-
分类问题
这里解释下,为什么GBDT解决分类问题用的也是回归树。因为GBDT的根本就是在不断地拟合残差,残差的加减可以逐渐减小偏差。而分类树输出的是类别,他们之间的加减是没有意义的。分类问题和回归问题的最大不同在于损失函数的定义以及节点输出值的确定,其他都是一样的。
-
二分类
-
对数似然损失函数
其中:
-
计算负梯度
-
计算树的叶子节点的最佳的输出值
对于树Ta的第h个叶子节点,其输出值为:
-
最终的类别
迭代完成后,得到的模型为F_m,对于样本X,分别计算其属于1和-1的概率:
概率较大的对应的类别就是预测类别。
-
-
多分类
对于多分类任务,GDBT采用OneVsOther,也就是对每个类别训练m个弱模型。假设有K个类别,那么训练完之后总共有K*m颗树。
-
多分类对数似然损失函数
-
计算负梯度
因为每次迭代都需要对每一个类别都构建一个回归树F_k(X), k=1,2,……,K。
因此每个样本都要计算k次的负梯度,只不过每一次针对的类别不同。
-
计算树的叶子节点的最佳的输出值
-
最终的类别
到最后,每个类别都会得到m个回归树,将每个类别回归树的结果集成起来,会得到K个最终的集成结果。
对于一个样本而言,会相应的得到K个结果,然后按照Softmax的方式,得到这个样本最终的类别。
-
-
-
Files
GBDT
Folders and files
| Name | Name | Last commit date | ||
|---|---|---|---|---|
parent directory.. | ||||

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}