(Feel free to suggest changes)
- Merging Phoneme and Char representations: https://arxiv.org/pdf/1811.07240.pdf
- Tacotron Transfer Learning : https://arxiv.org/pdf/1904.06508.pdf
- Phoneme Timing From Attention: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8683827
- Semi-Supervised Training to Improve Data Efficiency in End-to-End Speech Synthesis - https://arxiv.org/pdf/1808.10128.pdf
- Listening while Speaking: Speech Chain by Deep Learning - https://arxiv.org/pdf/1707.04879.pdf
- Generelized End-to-End Loss for Speaker Verification: https://arxiv.org/pdf/1710.10467.pdf
- Es-Tacotron2: Multi-Task Tacotron 2 with Pre-Trained Estimated Network for Reducing the Over-Smoothness Problem: https://www.mdpi.com/2078-2489/10/4/131/pdf
- Against Over-Smoothness
- FastSpeech: https://arxiv.org/pdf/1905.09263.pdf
- Learning Singing From Speech: https://arxiv.org/pdf/1912.10128.pdf
- TTS-GAN: https://arxiv.org/pdf/1909.11646.pdf
- they use duration and linguistic features for en2en TTS.
- Close to WaveNet performance.
- DurIAN: https://arxiv.org/pdf/1909.01700.pdf
- Duration aware Tacotron
- MelNet: https://arxiv.org/abs/1906.01083
- AlignTTS: https://arxiv.org/pdf/2003.01950.pdf
- Unsupervised Speech Decomposition via Triple Information Bottleneck
- FlowTron: https://arxiv.org/pdf/2005.05957.pdf
- Inverse Autoregresive Flow on Tacotron like architecture
- WaveGlow as vocoder.
- Speech style embedding with Mixture of Gaussian model.
- Model is large and havier than vanilla Tacotron
- MOS values are slighly better than public Tacotron implementation.
- Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention : https://arxiv.org/pdf/1710.08969.pdf
End-to-End Adversarial Text-to-Speech: http://arxiv.org/abs/2006.03575 (Click to Expand)
- end2end feed-forward TTS learning.
- Character alignment has been done with a separate aligner module.
- The aligner predicts length of each character.
- The center location of a char is found wrt the total length of the previous characters.
- Char positions are interpolated with a Gaussian window wrt the real audio length.
- audio output is computed in mu-law domain. (I don't have a reasoning for this)
- use only 2 secs audio windows for traning.
- GAN-TTS generator is used to produce audio signal.
- RWD is used as a audio level discriminator.
- MelD: They use BigGAN-deep architecture as spectrogram level discriminator regading the problem as image reconstruction.
- Spectrogram loss
- Using only adversarial feed-back is not enough to learn the char alignments. They use a spectrogram loss b/w predicted spectrograms and ground-truth specs.
- Note that model predicts audio signals. Spectrograms above are computed from the generated audio.
- Dynamic Time Wraping is used to compute a minimal-cost alignment b/w generated spectrograms and ground-truth.
- It involves a dynamic programming approach to find a minimal-cost alignment.
- Aligner length loss is used to penalize the aligner for predicting different than the real audio length.
- They train the model with multi speaker dataset but report results on the best performing speaker.
- Ablation Study importance of each component: (LengthLoss and SpectrogramLoss) > RWD > MelD > Phonemes > MultiSpeakerDataset.
- My 2 cents: It is a feed forward model which provides end-2-end speech synthesis with no need to train a separate vocoder model. However, it is very complicated model with a lot of hyperparameters and implementation details. Also the final result is not close to the state of the art. I think we need to find specific algorithms for learning character alignments which would reduce the need of tunning a combination of different algorithms.

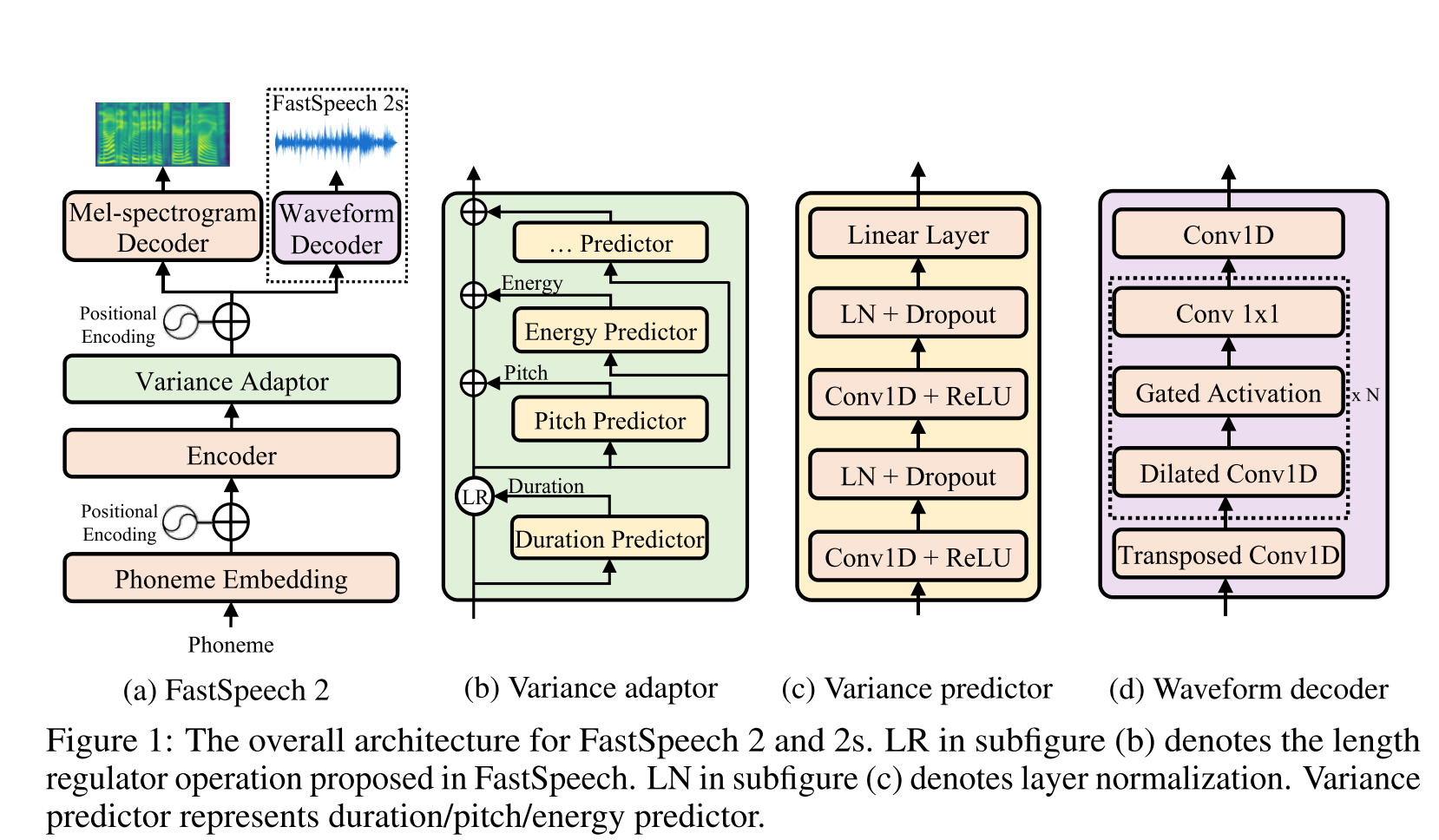
Fast Speech2: http://arxiv.org/abs/2006.04558 (Click to Expand)
- Use phoneme durations generated by MFA as labels to train a length regulator.
- Thay use frame level F0 and L2 spectrogram norms (Variance Information) as additional features.
- Variance predictor module predicts the variance information at inference time.
- Ablation study result improvements: model < model + L2_norm < model + L2_norm + F0
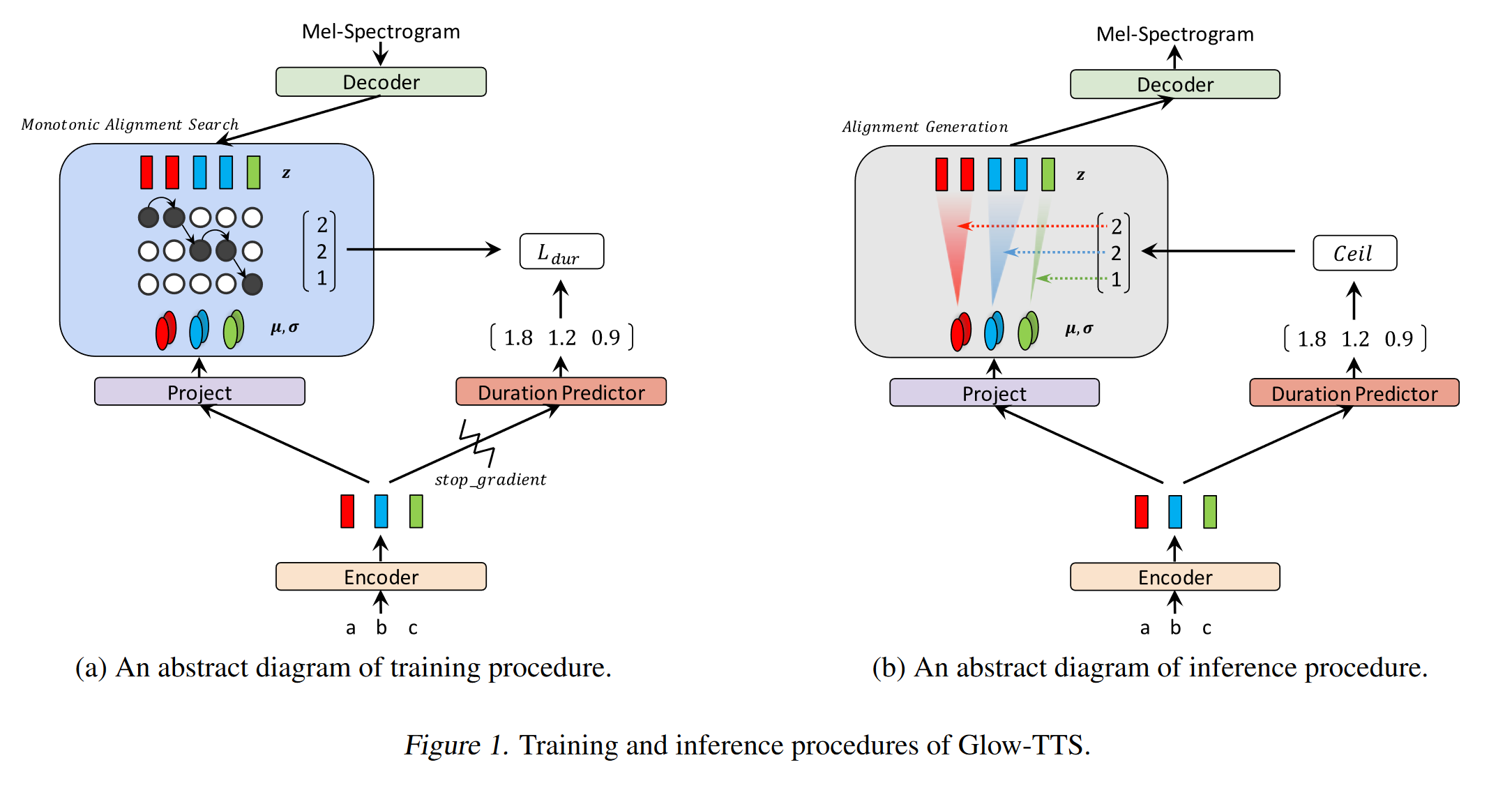
Glow-TTS: https://arxiv.org/pdf/2005.11129.pdf (Click to Expand)
- Use Monotonic Alignment Search to learn the alignment b/w text and spectrogram
- This alignment is used to train a Duration Predictor to be used at inference.
- Encoder maps each character to a Gaussian Distribution.
- Decoder maps each spectrogram frame to a latent vector using Normalizing Flow (Glow Layers)
- Encoder and Decoder outputs are aligned with MAS.
- At each iteration first the most probable alignment is found by MAS and this alignment is used to update mode parameters.
- A duration predictor is trained to predict the number of spectrogram frames for each character.
- At inference only the duration predictor is used instead of MAS
- Encoder has the architecture of the TTS transformer with 2 updates
- Instead of absolute positional encoding, they use realtive positional encoding.
- They also use a residual connection for the Encoder Prenet.
- Decoder has the same architecture as the Glow model.
- They train both single and multi-speaker model.
- It is showed experimentally, Glow-TTS is more robust against long sentences compared to original Tacotron2
- 15x faster than Tacotron2 at inference
- My 2 cents: Their samples sound not as natural as Tacotron. I believe normal attention models still generate more natural speech since the attention learns to map characters to model outputs directly. However, using Glow-TTS might be a good alternative for hard datasets.
- Samples: https://github.com/jaywalnut310/glow-tts
- Repository: https://github.com/jaywalnut310/glow-tts
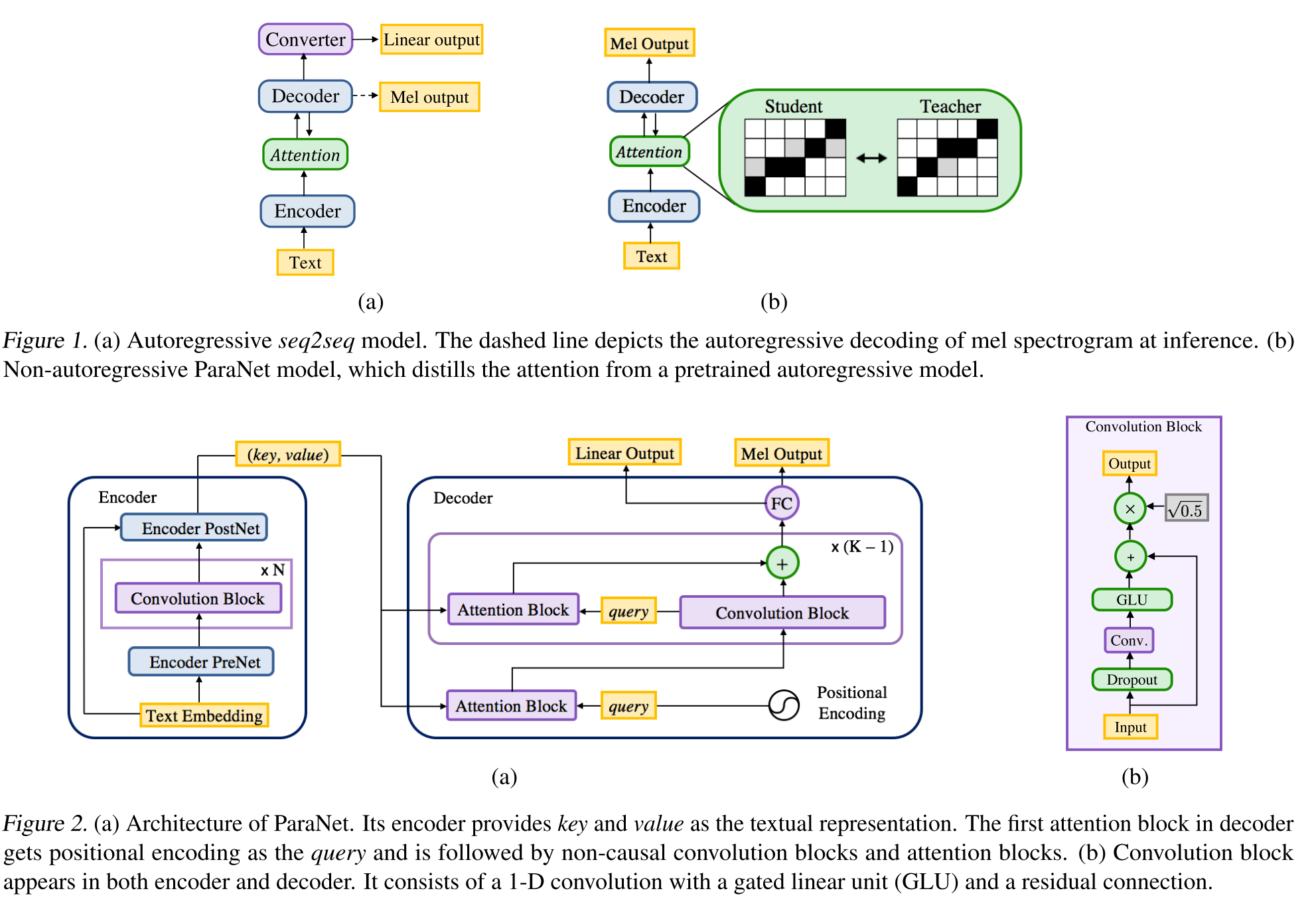
Non-Autoregressive Neural Text-to-Speech: http://arxiv.org/abs/1905.08459 (Click to Expand)
- A derivation of Deep Voice 3 model using non-causal convolutional layers.
- Teacher-Student paradigm to train annon-autoregressive student with multiple attention blocks from an autoregressive teacher model.
- The teacher is used to generate text-to-spectrogram alignments to be used by the student model.
- The model is trained with two loss functions for attention alignment and spectrogram generation.
- Multi attention blocks refine the attention alignment layer by layer.
- The student uses dot-product attention with query, key and value vectors. The query is only positinal encoding vectors. The key and the value are the encoder outputs.
- Proposed model is heavily tied to the positional encoding which also relies on different constant values.
Double Decoder Consistency: https://erogol.com/solving-attention-problems-of-tts-models-with-double-decoder-consistency (Click to Expand)
- The model uses a Tacotron like architecture but with 2 decoders and a postnet.
- DDC uses two synchronous decoders using different reduction rates.
- The decoders use different reduction rates thus they compute outputs in different granularities and learn different aspects of the input data.
- The model uses the consistency between these two decoders to increase robustness of learned text-to-spectrogram alignment.
- The model also applies a refinement to the final decoder output by applying the postnet iteratively multiple times.
- DDC uses Batch Normalization in the prenet module and drops Dropout layers.
- DDC uses gradual training to reduce the total training time.
- We use a Multi-Band Melgan Generator as a vocoder trained with Multiple Random Window Discriminators differently than the original work.
- We are able to train a DDC model only in 2 days with a single GPU and the final model is able to generate faster than real-time speech on a CPU.
Demo page: https://erogol.github.io/ddc-samples/
Code: https://github.com/mozilla/TTS

Parallel Tacotron2: http://arxiv.org/abs/2103.14574 (Click to Expand)
- Does not require external duration information.
- Solves the alignment issues between the real and ground-truth spectrograms by Soft-DTW loss.
- Predicted durations are converted to alignment by a learned conversion function, rather than a Length Regulator, to solve rounding issues.
- Learns an attention map over "Token Boundary Grids" which are computed from predicted durations.
- Decoder is built on 6 "light-weight Convolutions" blocks.
- A VAE is used to project input spectrograms to latent features and merged with the characterr embeddings as an input to the network.
- Soft-DTW is computationally intensive since it computes pairwise difference for all the spectrogram frames. They contrain it with a certain diagonal window to reduce the overhead.
- The final duration objective is the sum of Duration Loss, VAE loss and Spectrogram Loss.
- They only use proprietary datasets for the experiments 😦.
- Achieves the same MOS with the Tacotron2 model and outperforms ParallelTacotron.
- Demo page: https://google.github.io/tacotron/publications/parallel_tacotron_2/index.html
- Code: No code so far

WaveGrad2: https://arxiv.org/pdf/2106.09660.pdf (Click to Expand)
- It computes the raw waveform directly from a phoneme sequence.
- A Tacotron2 like encoder model is used to compute a hidden representation from phonemes.
- Non-Attentive Tacotron like soft duration predictor to align the hidden represenatation with the output.
- They expand the hidden representation with the predicted durations and sample a certain window to convert to a waveform.
- They explored different window sizes netween 64 and 256 frames corresponding to 0.8 and 3.2 secs of speech. They found that the larger is the better.
- Demo page: Nothing so far
- Code: No code so far


- Training Multi-Speaker Neural Text-to-Speech Systems using Speaker-Imbalanced Speech Corpora - https://arxiv.org/abs/1904.00771
- Deep Voice 2 - https://papers.nips.cc/paper/6889-deep-voice-2-multi-speaker-neural-text-to-speech.pdf
- Sample Efficient Adaptive TTS - https://openreview.net/pdf?id=rkzjUoAcFX
- WaveNet + Speaker Embedding approach
- Voice Loop - https://arxiv.org/abs/1707.06588
- MODELING MULTI-SPEAKER LATENT SPACE TO IMPROVE NEURAL TTS QUICK ENROLLING NEW SPEAKER AND ENHANCING PREMIUM VOICE - https://arxiv.org/pdf/1812.05253.pdf
- Transfer learning from speaker verification to multispeaker text-to-speech synthesis - https://arxiv.org/pdf/1806.04558.pdf
- Fitting new speakers based on a short untranscribed sample - https://arxiv.org/pdf/1802.06984.pdf
- Generalized end-to-end loss for speaker verification - https://arxiv.org/abs/1710.10467
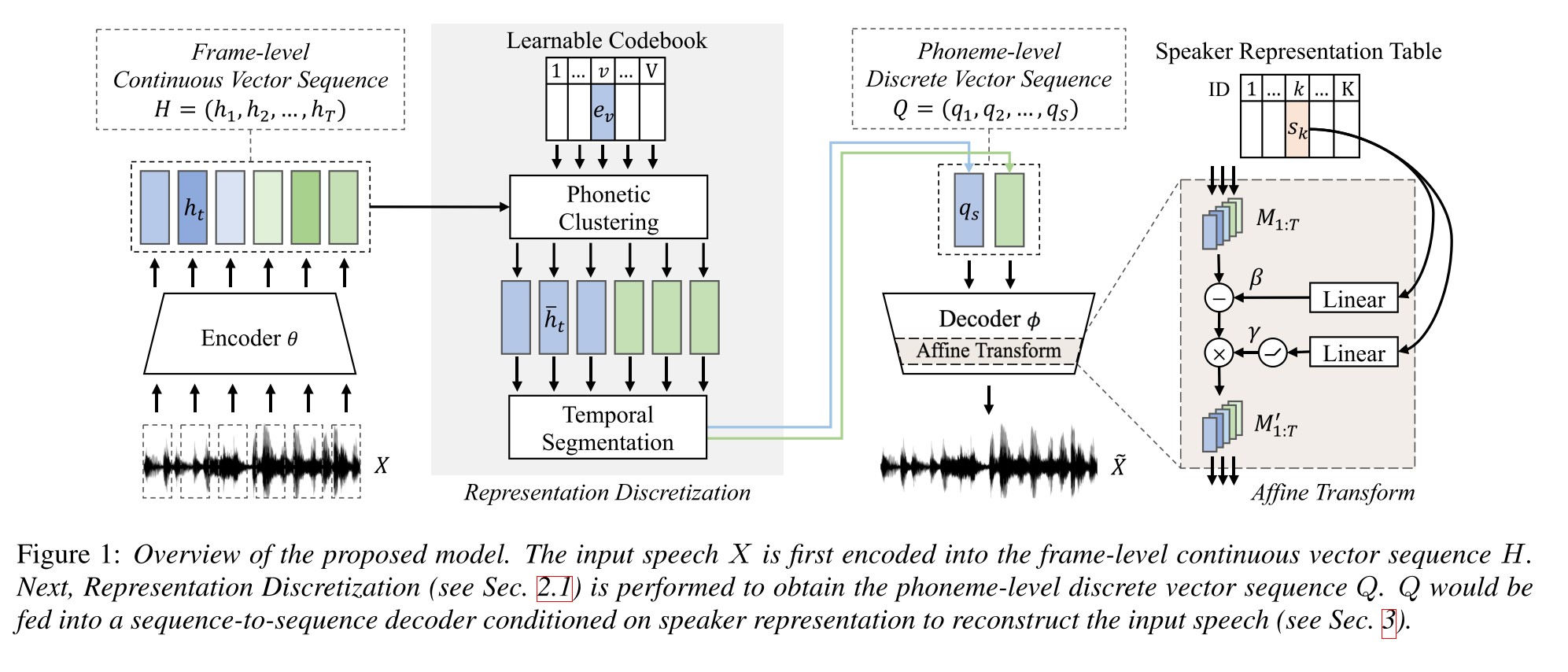
Semi-supervised Learning for Multi-speaker Text-to-speech Synthesis Using Discrete Speech Representation: http://arxiv.org/abs/2005.08024
- Train a multi-speaker TTS model with only an hour long paired data (text-to-voice alignment) and more unpaired (only voide) data.
- It learns a code book with each code word corresponds to a single phoneme.
- The code-book is aligned to phonemes using the paired data and CTC algorithm.
- This code book functions like a proxy to implicitly estimate the phoneme sequence of the unpaired data.
- They stack Tacotron2 model on top to perform TTS using the code word embeddings generated by the initial part of the model.
- They beat the benchmark methods in 1hr long paired data setting.
- They don't report full paired data results.
- They don't have a good ablation study which could be interesting to see how different parts of the model contribute to the performance.
- They use Griffin-Lim as a vocoder thus there is space for improvement.
Demo page: https://ttaoretw.github.io/multispkr-semi-tts/demo.html
Code: https://github.com/ttaoREtw/semi-tts
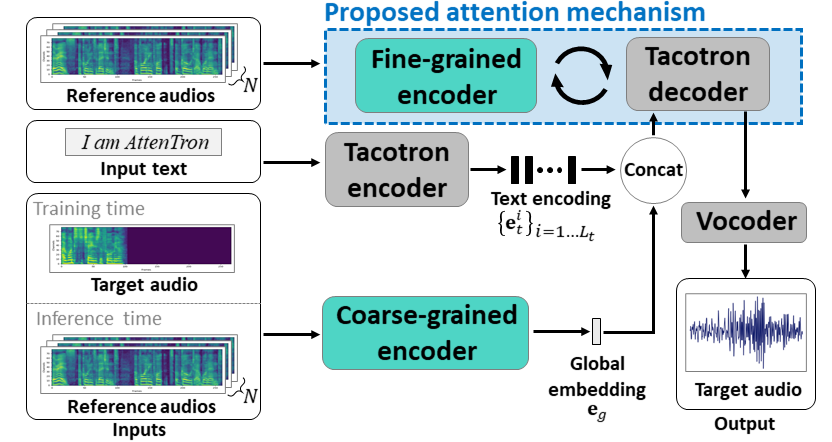
Attentron: Few-shot Text-to-Speech Exploiting Attention-based Variable Length Embedding: https://arxiv.org/abs/2005.08484
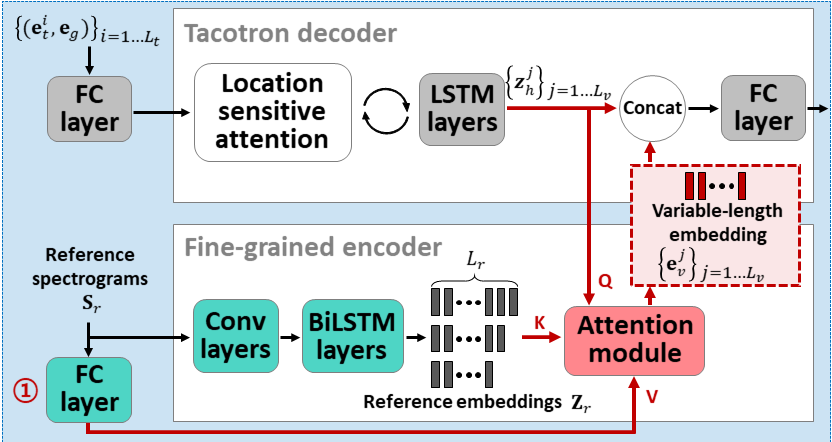
- Use two encoders to learn speaker depended features.
- Coarse encoder learns a global speaker embedding vector based on provided reference spectrograms.
- Fine encoder learns a variable length embedding keeping the temporal dimention in cooperation with a attention module.
- The attention selects important reference spectrogram frames to synthesize target speech.
- Pre-train the model with a single speaker dataset first (LJSpeech for 30k iters.)
- Fine-tune the model with a multi-speaker dataset. (VCTK for 70k iters.)
- It achieves slightly better metrics in comparison to using x-vectors from speaker classification model and VAE based reference audio encoder.
Demo page: https://hyperconnect.github.io/Attentron/
Towards Universal Text-to-Speech: http://www.interspeech2020.org/uploadfile/pdf/Wed-3-4-3.pdf
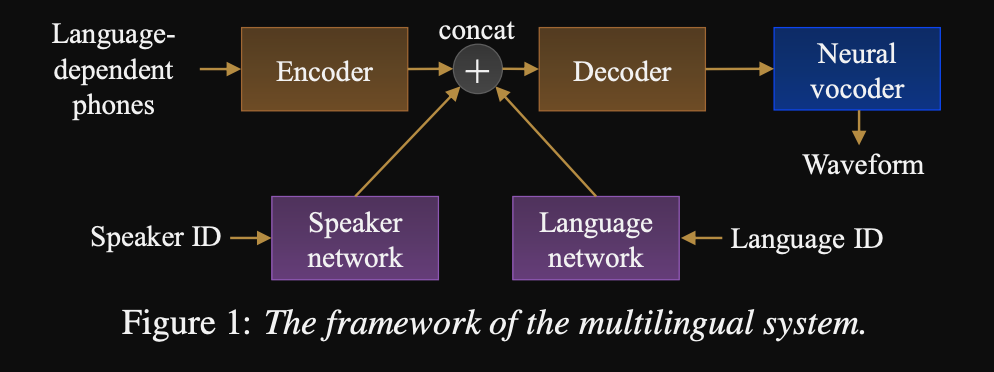
- A framework for a sequence to sequence multi-lingual TTS
- The model is trained with a very large, highly unbalanced dataset.
- The model is able to learn a new language with 6 minutes and a new speaker with 20 seconds of data after the initial training.
- The model architecture is a Transformer based Encoder-Decoder network with a Speaker Network and a Language Network for the speaker and language conditinoning. The outputs of these networks are concatenated to the Encoder output.
- The conditioning networks take a one-hot vector representing the speaker or language ID and projects it to a conditioning representation.
- They use a WaveNet vocoder for converting predicted Mel-Spectrograms to the waveform output.
- They use language depended phonemes inputs that are not shared among languages.
- They sample each batch based on the inverse frequency of each language in the dataset. Thus each training batch has a uniform distribution over languages, alleviating the language imbalance in the training dataset.
- For learning new speakers/languages, they fine-tune the Encoder-Decoder model with the conditioning networks. They don’t train the WaveNet model.
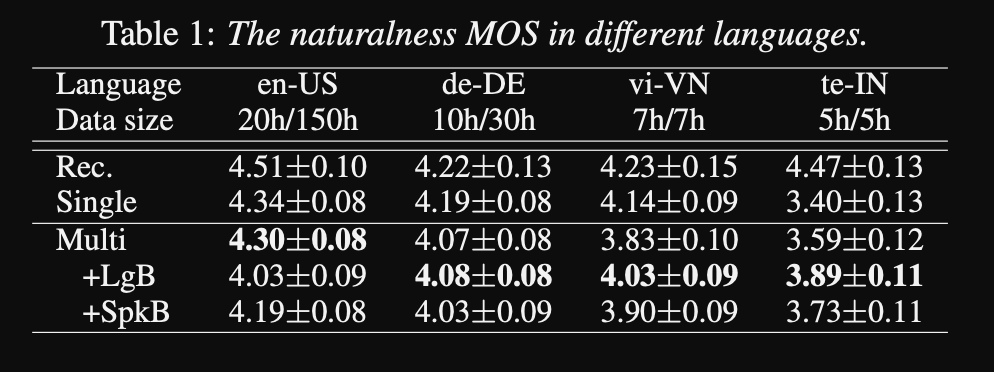
- They use 1250 hours professional recordings from 50 languages for the training.
- They use 16khz sampling rate for all the audio samples and trim silences at the beginning and the end of each clip.
- They use 4 V100 GPUs for training but they don’t mention how long they trained the model.
- The results show that single speaker models are better than the proposed approach in MOS metric.
- Also using conditioning networks is important for the long-tail languages in the dataset as they improve the MOS metric for them but impair the performance for the high-resource languages.
- When they add a new speaker, they observe that using more than 5 minutes of data degrades the model performance. They claim that since these recordings are not as clean as the original recordings, using more of them affects the model’s general performance.
- The multi-lingual model is able to train with only 6 minutes of data for new speakers and languages whereas a single speaker model requires 3 hours to train and cannot even attain similar MOS values as the 6 minutes multi-lingual model.
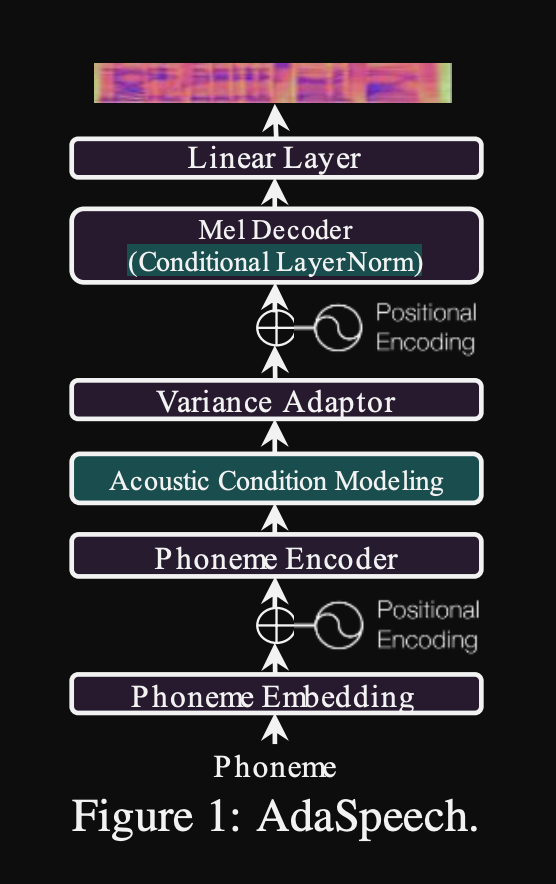
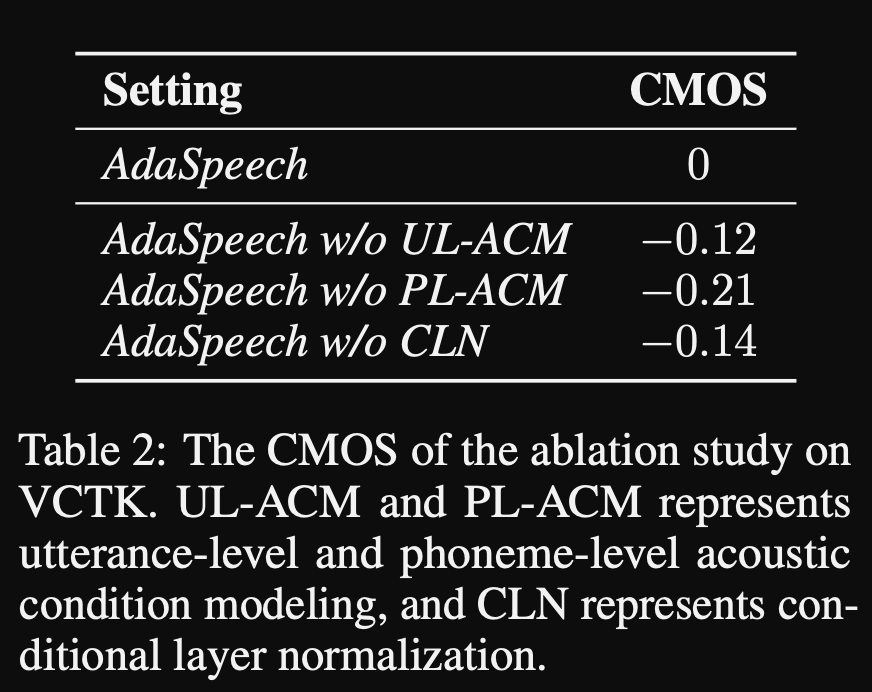
AdaSpeech: Adaptive Text to Speech for Custom Voice: https://openreview.net/pdf?id=Drynvt7gg4L
- They proposed a system that can adapt to different input acoustic properties of users and it uses minimum number of parameters to achieve this.
- The main architecture is based on FastSpeech2 model that uses Pitch and Variance predictors to learn the finer granularities of the input speech.
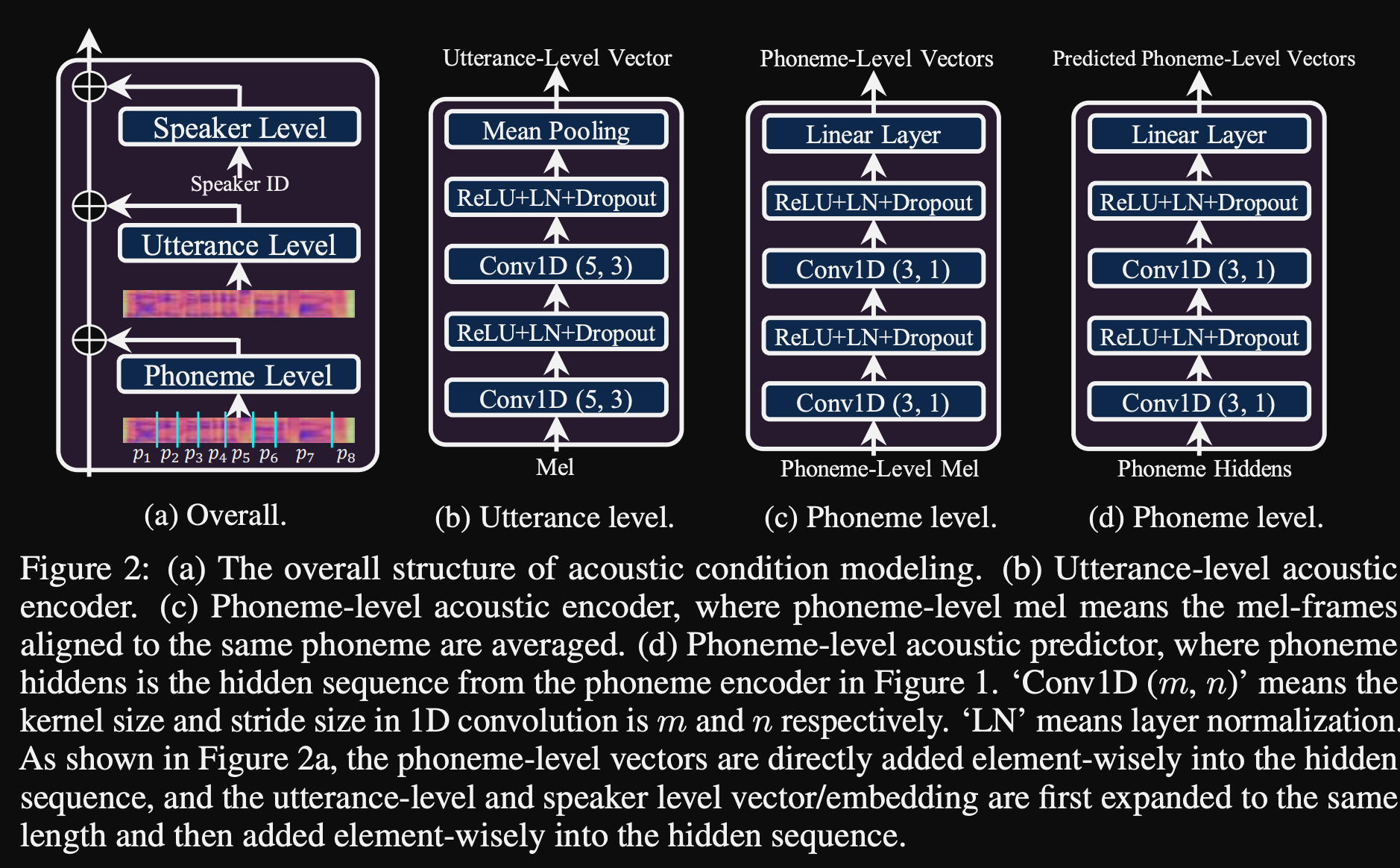
- They use 3 additional conditioning networks.
- Utterance level. It takes mel-spectrogram of the reference speech as input.
- Phoneme level. It takes phoneme level mel-spectrograms as input and computes phoneme-level conditioning vectors. Phoneme-level mel-spectrograms are computed by taking the average spectrogram frame in the duration of each phoneme.
- Phoneme level 2. It takes phoneme encoder outputs as inputs. This differs from the network above by just using the phoneme information without seeing the spectrograms.
- All these conditioning networks and the back-bone FastSpeech2 uses Layer Normalisation layers.
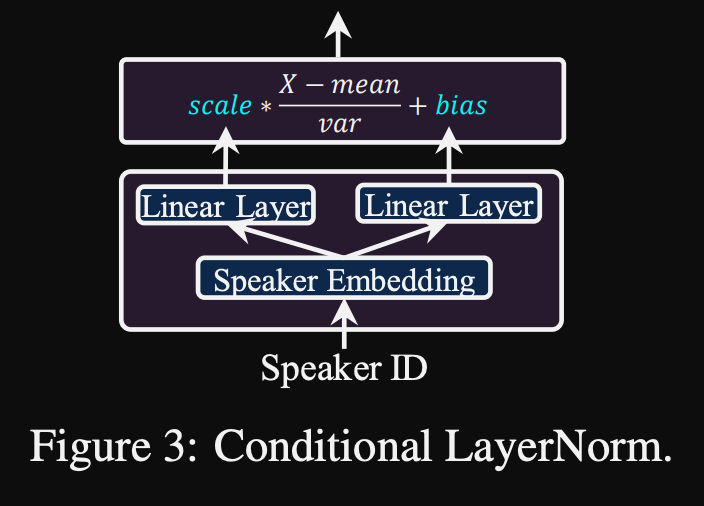
- Conditional layer normalisation. They propose fine-tuning only the scale and bias parameters of each layer normalisation layer when the model is fine-tuned for a new speaker. They train a speaker conditioning module for each Layer Norm layer that outputs a scale and a bias values. (They use one speaker conditioning module per Transformer block.)
- It means that you only store the Speaker Conditioning module for each new speaker and predict the scale and bias values at inference as you keep the rest of the model the same.
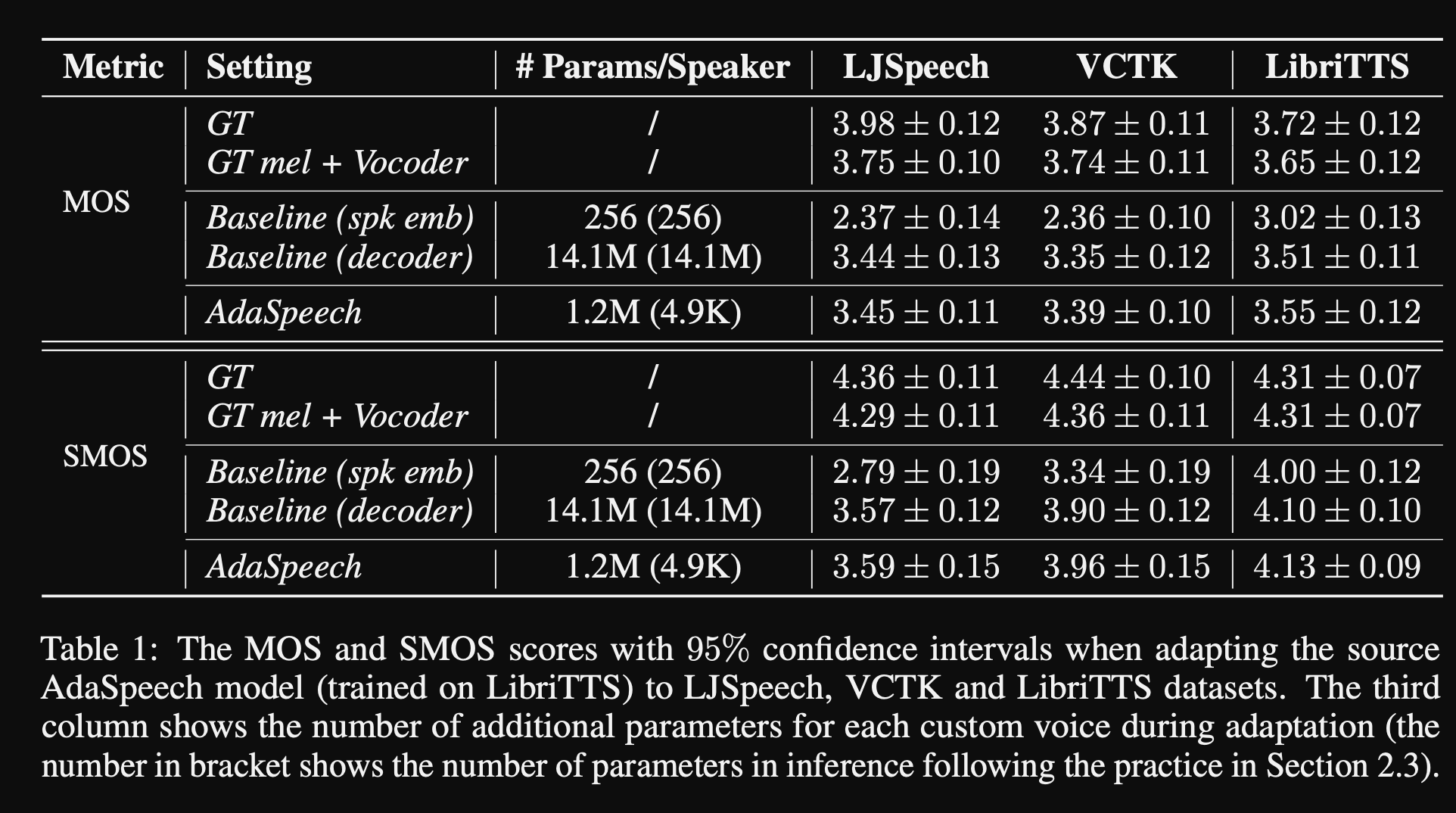
- In the experiments, they train pre-train the model on LibriTTS dataset and fine-tune it with VCTK and LJSpeech
- The results show that using Conditional Layer Normalisation achieves better than their 2 baselines which use only speaker embedding and decoder network fine-tunning.
- Their ablation study shows that the most significant part of the model is the “Phoneme level” network followed by Conditional Layer Normalisation and “Utterance level” network in an order.
- One important down-side of the paper is that there is almost no comparison with the literature and it makes the results harder to assess objectively.
Demo page: https://speechresearch.github.io/adaspeech/

- Location-Relative Attention Mechanisms for Robust Long-Formspeech Synthesis - https://arxiv.org/pdf/1910.10288.pdf
-
MelGAN: https://arxiv.org/pdf/1910.06711.pdf
-
ParallelWaveGAN: https://arxiv.org/pdf/1910.11480.pdf
- Multi scale STFT loss
- ~1M model parameters (very small)
- Slightly worse than WaveRNN
-
Improving FFTNEt
-
FFTnet
-
SPEECH WAVEFORM RECONSTRUCTION USING CONVOLUTIONAL NEURALNETWORKS WITH NOISE AND PERIODIC INPUTS
- 150.162.46.34:8080/icassp2019/ICASSP2019/pdfs/0007045.pdf
-
Towards Achieveing Robust Universal Vocoding
-
LPCNet
-
ExciteNet
-
GELP: GAN-Excited Linear Prediction for Speech Synthesis fromMel-spectrogram
-
High Fidelity Speech Synthesis with Adversarial Networks: https://arxiv.org/abs/1909.11646
- GAN-TTS, end-to-end speech synthesis
- Uses duration and linguistic features
- Duration and acoustic features are predicted by additional models.
- Random Window Discriminator: Ingest not the whole Voice sample but random windows.
- Multiple RWDs. Some conditional and some unconditional. (conditioned on input features)
- Punchline: Use randomly sampled windows with different window sizes for D.
- Shared results sounds mechanical that shows the limits of non-neural acoustic features.
-
Multi-Band MelGAN: https://arxiv.org/abs/2005.05106
- Use PWGAN losses instead of feature-matching loss.
- Using a larger receptive field boosts model performance significantly.
- Generator pretraining for 200k iters.
- Multi-Band voice signal prediction. The output is summation of 4 different band predictions with PQMF synthesis filters.
- Multi-band model has 1.9m parameters (quite small).
- Claimed to be 7x faster than MelGAN
- On a Chinese dataset: MOS 4.22
-
WaveGLow: https://arxiv.org/abs/1811.00002
- Very large model (268M parameters)
- Hard to train since on 12GB GPU it can only takes batch size 1.
- Real-time inference due to the use of convolutions.
- Based on Invertable Normalizing Flow. (Great tutorial https://blog.evjang.com/2018/01/nf1.html )
- Model learns and invetible mapping of audio samples to mel-spectrograms with Max Likelihood loss.
- In inference network runs in reverse direction and give mel-specs are converted to audio samples.
- Training has been done using 8 Nvidia V100 with 32GB ram, batch size 24. (Expensive)
-
SqueezeWave: https://arxiv.org/pdf/2001.05685.pdf , code: https://github.com/tianrengao/SqueezeWave
- ~5-13x faster than real-time
- WaveGlow redanduncies: Long audio samples, upsamples mel-specs, large channel dimensions in WN function.
- Fixes: More but shorter audio samples as input, (L=2000, C=8 vs L=64, C=256)
- L=64 matchs the mel-spec resolution so no upsampling necessary.
- Use depth-wise separable convolutions in WN modules.
- Use regular convolution instead of dilated since audio samples are shorter.
- Do not split module outputs to residual and network output, assuming these vectors are almost identical.
- Training has been done using Titan RTX 24GB batch size 96 for 600k iterations.
- MOS on LJSpeech: WaveGLow - 4.57, SqueezeWave (L=128 C=256) - 4.07 and SqueezeWave (L=64 C=256) - 3.77
- Smallest model has 21K samples per second on Raspi3.
WaveGrad: https://arxiv.org/pdf/2009.00713.pdf
- It is based on Probability Diffusion and Lagenvin Dynamics
- The base idea is to learn a function that maps a known distribution to target data distribution iteratively.
- They report 0.2 real-time factor on a GPU but CPU performance is not shared.
- In the example code below, the author reports that the model converges after 2 days of training on a single GPU.
- MOS scores on the paper are not compherensive enough but shows comparable performance to known models like WaveRNN and WaveNet.
Code: https://github.com/ivanvovk/WaveGrad

- Tacotron 2 : https://www.youtube.com/watch?v=2iarxxm-v9w
- Talk on Pushing the Frontier of Neural Text-to-Speech, by Xu Tan, 2021, https://youtu.be/MA8PCvmr8B0
- Talk on Generative Model-Based Text-to-Speech Synthesis, by Heiga Zen, 2017
- Tutorials on Neural Parametric Text-to-Speech Synthesis at ISCA Odyessy 2020, by Xin Wang, 2020
- ISCA Speech Processing Course on Neural vocoders, 2022
- Basic components of neural vocoders: https://youtu.be/M833q5I-ZYs
- Deep generative models for speech compression (LPCNet): https://youtu.be/7KsnFx3pLgw
- Neural auto-regressive, source-filter and glottal vocoders: https://youtu.be/gPrmxdberX0
- Speech synthesis from neural decoding of spoken sentences | AISC : https://www.youtube.com/watch?v=MNDtMDPmnMo
- Generative Text-to-Speech Synthesis : https://www.youtube.com/watch?v=j4mVEAnKiNg
- SPEECH SYNTHESIS FOR THE GAMING INDUSTRY : https://www.youtube.com/watch?v=aOHAYe4A-2Q
- Modern Text-to-Speech Systems Review : https://www.youtube.com/watch?v=8rXLSc-ZcRY
- Tutorials on Selected Neural Vocoders: https://github.com/nii-yamagishilab/project-NN-Pytorch-scripts/tree/master/tutorials/b1_neural_vocoder
- Text to Speech Deep Learning Architectures : http://www.erogol.com/text-speech-deep-learning-architectures/