[demo] add grafana and prometheus #456
Conversation
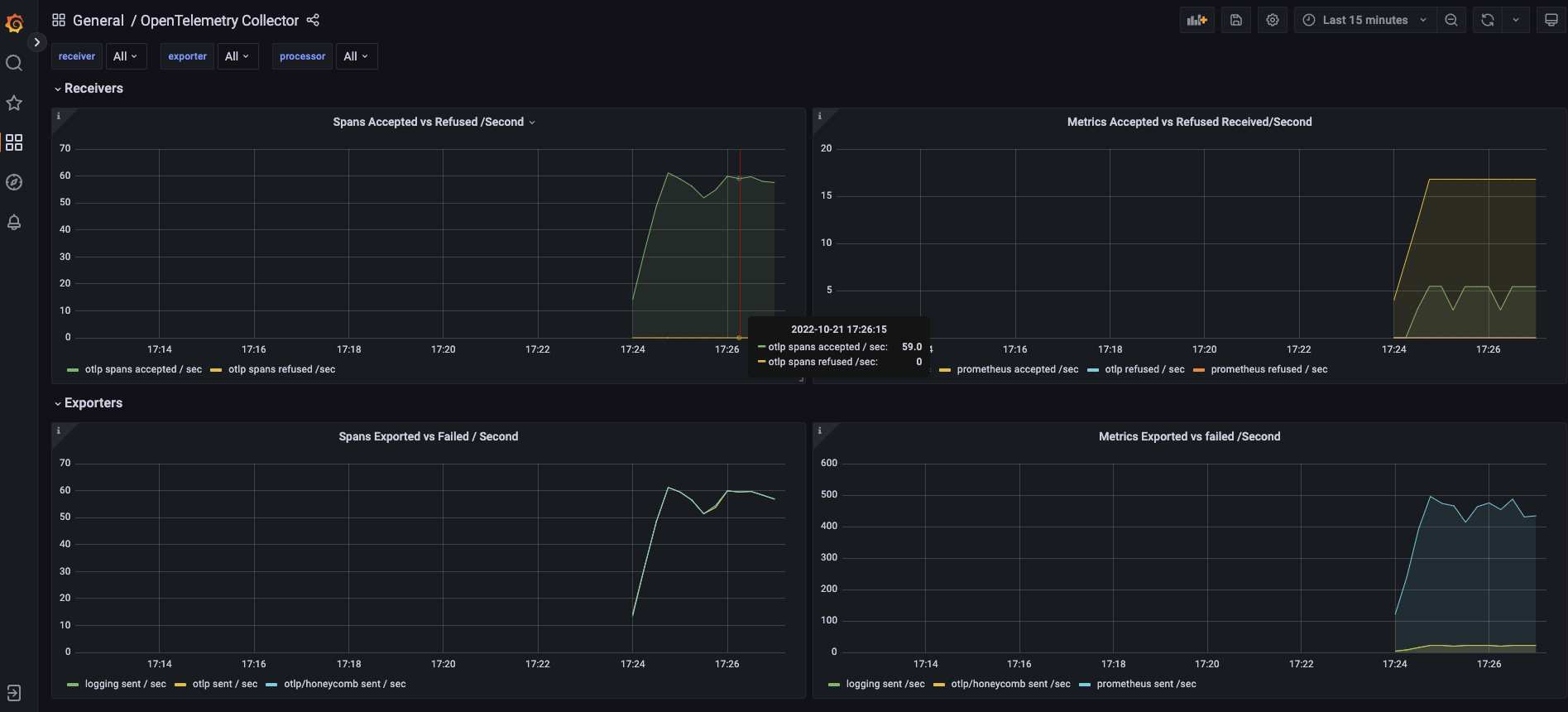
Yes. This is the OpenTelemetry collector dashboard |
|
@TylerHelmuth for managing helm dependencies Renovate is a good option. @puckpuck @dmitryax @TylerHelmuth I may be biased here but while I can see the value of adding Prometheus/Alertmanager/Grafana components to any otel setup, I think the user should deploy and manage them separately and not as part of this helm chart as dependencies. Some thoughts:
|
|
@Allex1 the intent here is to keep this on par with deploying the demo today with docker compose. This isn't meant for people to use in production, but rather have one-stop batteries included solution to seeing it all just work. I'm up for suggestions on other ways to include these components, but to make this work for anyone on a new cluster we will need them. |
|
I think it makes sense to add Grafana and Prometheus to the demo chart to see a fully featured e2e open-source observability solution. We also need Elasticsearch for logs, right? My concern is similar to the one raised by @Allex1, I don't like how complicated the values.yaml becomes and how many options we supply to the sub-charts to get the desired behavior. I would like to ask you to reduce the custom sub-chart values as much as possible and rely more on defaults. E.g. if we really need spanmetrics processor, it would be nice to add it as a preset in the collector chart to keep the |
|
I can crank out a spanmetrics processor preset tomorrow since I'm not at Kubecon. |
We haven't added logging to the demo yet, once it's there we'll integrate it into the helm chart.
Part of the goal of the demo that it should be very customizable; We don't want forks to proliferate. I also don't necessarily think that the demo should be setting guidance for the other helm components (e.g., we use spanmetrics processor because we don't do any sampling right now, this way we can get RED metrics for each endpoint using spans.) I'm not opposed to pulling parts out into the other charts, but tbf I'd also like to reduce the surface area of this chart entirely and migrate things like the collector to an operator config rather than being deployed with the application itself. |
|
@dmitryax I actually don't think the preset I would create would help the demo chart? I think a default spanmetricsprocessor preset would be configured to use the existing metrics pipeline and the logging exporter, whereas the demo needs to use the prometheus exporter. We wouldn't want the collector preset to make any assumptions about where the data would get exported. So we can still make a spanmetrics processor as a preset as it holds individual value, but it won't help simplify this PR. |
There was a problem hiding this comment.
@puckpuck can you review the 3 subchart entries in the values.yaml and confirm that all values defined are necessary?
I'm not saying we should reduce the ability to customize the helm chart including sub-charts. I just want to avoid adding unnecessary predefined configuration in the default values.yaml for the sub-charts. PTAL at the PR comments. For example, if we partially override the collector's config as it's currently done in this PR, it'll be hard to maintain it going forward - a change to the collector's config interface or default collector chart configuration may break it. So I think it's better to rely on the default configuration of the collector chart instead of partially overriding it. |
@TylerHelmuth why not? Won't it be 2 changes in this PR: add spanmetrics preset + replacement of the exporter in the config? |
|
Also, I don't think we should strife for 1to1 parity with the docker-compose setup. The demo deployment in k8s likely needs other features like k8s attributes processor which is not needed in the docker-compose setup. |
|
Imo helm charts should be as contained as possible. As an end user you have all the flexibility to add any other charts next to this one under a parent chart that you maintain within your project. |
|
Sorry about the delay. I was at Kubecon for the week. I believe I have addressed all the concerns noted. I did my best to minimize the setting overrides for the sub-charts. I know this is a big add to this chart, but these are 2 key components required for that all-in experience we want to provide. For people that already have a Prometheus and Grafana setup, we have facilities in this chart to use their own existing services, and I will make sure that experience is well documented here and/or the demo repository in a future PR. |
| @@ -11,9 +11,17 @@ maintainers: | |||
| - name: tylerhelmuth | |||
| - name: wph95 | |||
| icon: https://opentelemetry.io/img/logos/opentelemetry-logo-nav.png | |||
| appVersion: "0.6.1-beta" | |||
| appVersion: "1.0.0" | |||
There was a problem hiding this comment.
Can we take the 1.0 images in this PR without the frontendproxy stuff?
There was a problem hiding this comment.
Yes. The frontend proxy is an additional layer to help for browser-initiated tracing span data, which is a separate thing. We also use it to limit the exposed ports. All that is part of the next PR.
…-grafana # Conflicts: # charts/opentelemetry-demo/Chart.yaml # charts/opentelemetry-demo/examples/default/rendered/component.yaml # charts/opentelemetry-demo/examples/default/rendered/jaeger.yaml
|
@dmitryax ready for re-review |
This adds Grafana and Prometheus to the demo app. The sample OpenTelemetry Collector dashboard is also part of this deployment. Both are done as subcharts.
Grafana is setup to use anonymous login (similar to the demo)
Because the Prometheus chart does not use
tplfor ConfigMaps I couldn't use the same static scrape configs as specified in the demo. Instead, this uses a Kubernetes scraper for pods. The scrape will target pods with a specific annotation that is only present on the OpenTelemetry collector pod. The Collector itself also includes an additional Prometheus receiver to scrape its own self-metrics and emit them as part of the standard Prometheus exporter that gets scraped by the Prometheus server.