Align3R: Aligned Monocular Depth Estimation for Dynamic Videos Jiahao Lu*, Tianyu Huang*, Peng Li, Zhiyang Dou, Cheng Lin, Zhiming Cui, Zhen Dong, Sai-Kit Yeung, Wenping Wang, Yuan Liu Arxiv, 2024.
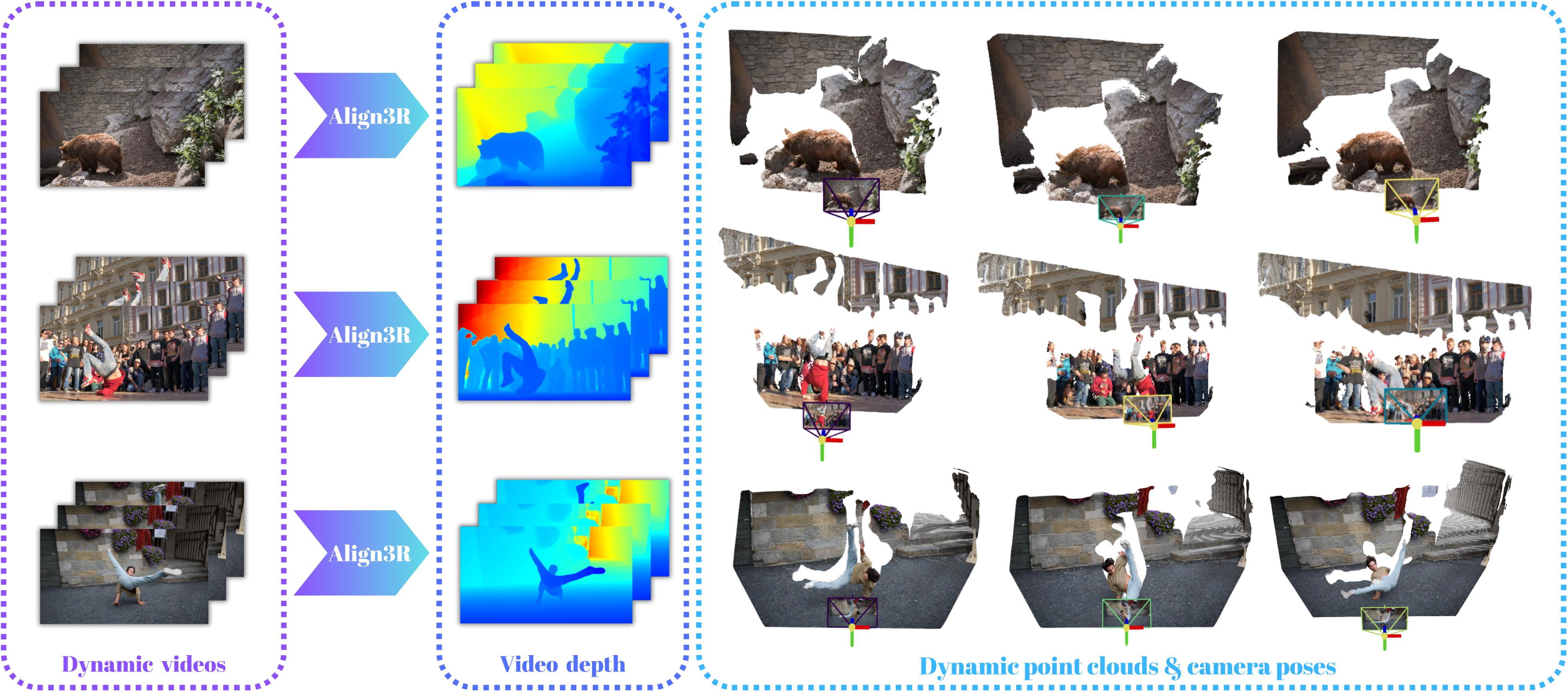
Align3R estimates temporally consistent video depth, dynamic point clouds, and camera poses from monocular videos.
- Clone this repo:
git clone [email protected]:jiah-cloud/Align3R.git- Install dependencies:
conda create -n align3r python=3.11 cmake=3.14.0
conda activate align3r
conda install pytorch torchvision pytorch-cuda=12.1 -c pytorch -c nvidia # use the correct version of cuda for your system
pip install -r requirements.txt
# Optional: you can also install additional packages to:
# - add support for HEIC images
# - add pyrender, used to render depthmap in some datasets preprocessing
# - add required packages for visloc.py
pip install -r requirements_optional.txt- Compile the cuda kernels for RoPE (as in CroCo v2):
cd croco/models/curope/
python setup.py build_ext --inplace
cd ../../../- Install the monocular depth estimation model Depth Pro and Depth Anything V2:
# Depth Pro
cd third_party/ml-depth-pro
pip install -e .
source get_pretrained_models.sh
# Depth Anything V2
pip install transformers==4.41.2- Download the corresponding model weights:
🔥🔥🔥 We upload our model weights to the Hugging Face, now you can download them via Align3R (Depth Pro) and Align3R (Depth Anything V2).
# DUSt3R
wget https://download.europe.naverlabs.com/ComputerVision/DUSt3R/DUSt3R_ViTLarge_BaseDecoder_512_dpt.pth
# Align3R
# If you cannot download the weights using the following scripts, please download them locally.
gdown --fuzzy https://drive.google.com/file/d/1-qhRtgH7rcJMYZ5sWRdkrc2_9wsR1BBG/view?usp=sharing
gdown --fuzzy https://drive.google.com/file/d/1PPmpbASVbFdjXnD3iea-MRIHGmKsS8Vh/view?usp=sharing
# Depth Pro
cd third_party/ml-depth-pro
source get_pretrained_models.sh
# Raft
gdown --fuzzy https://drive.google.com/file/d/1KJxQ7KPuGHlSftsBCV1h2aYpeqQv3OI-/view?usp=drive_link -O models/To train Align3R, you should download the following dataset:
- SceneFlow (Includes FlyingThings3D, Driving & Monkaa)
- VKITTI
- TartanAir
- Spring
- PointOdyssey
Then use the following script to preprocess the training datasets:
bash datasets_preprocess/preprocess_trainingset.shAfter preprocessing, our folder structure is as follows:
├── data
├── PointOdyssey_proc
│ ├── train
│ └── val
├── spring_proc
│ └── train
├── Tartanair_proc
├── vkitti_2.0.3_proc
└── SceneFlow
├── FlyingThings3D_proc
│ ├── TRAIN
│ │ ├── A
│ │ ├── B
│ │ └── C
│ └── TEST
│ ├── A
│ ├── B
│ └── C
├── Driving_proc
│ ├── 35mm_focallength
│ └── 15mm_focallength
└── Monkaa_procTo evaluate, you should download the following dataset:
- Sintel
- DAVIS
- Bonn
- TUM dynamics (Dynamic Objects: freiburg3)
For Bonn and TUM dynamics, you should use the following script to preprocess them:
bash datasets_preprocess/preprocess_testset.shOur folder structure is as follows:
├── data
├── bonn
│ └── rgbd_bonn_dataset
├── davis
│ └── DAVIS
│ ├── JPEGImages
│ │ ├── 480P
│ │ └── 1080P
│ ├── Annotations
│ │ ├── 480P
│ │ └── 1080P
│ └── ImageSets
│ ├── 480P
│ └── 1080P
├── MPI-Sintel
│ ├── MPI-Sintel-training_images
│ │ └── training
│ │ └── final
│ └── MPI-Sintel-depth-training
│ └── training
│ ├── camdata_left
│ └── depth
└── tum
To generate monocular depth maps, you should use the following script:
cd third_party/ml-depth-pro
bash infer.shPlease download the pretrained DUSt3R weight before training.
bash train.shYou can run the following demo code on any video. The input path can be either a mp4 video or an image folder.
bash demo.shbash depth_test.shPlease change the --dust3r_dynamic_model_path, --output_postfix, --dataset_name, --depth_prior_name.
# Depth Pro
CUDA_VISIBLE_DEVICES='0' python tool/depth_test.py --dust3r_dynamic_model_path="align3r_depthpro.pth" --align_with_lad --depth_max=70 --depth_prior_name=depthpro --dataset_name=sintel --eval --output_postfix="results/sintel_depth_ours_depthpro"
# Depth Anything V2
CUDA_VISIBLE_DEVICES='0' python tool/depth_test.py --dust3r_dynamic_model_path="align3r_depthanything.pth" --align_with_lad --depth_max=70 --depth_prior_name=depthanything --dataset_name=sintel --eval --output_postfix="results/sintel_depth_ours_depthanything" # Depth Pro
CUDA_VISIBLE_DEVICES='0' python tool/depth_test.py --dust3r_dynamic_model_path="align3r_depthpro.pth" --align_with_lad --depth_max=70 --depth_prior_name=depthpro --dataset_name=PointOdyssey --eval --output_postfix="results/PointOdyssey_depth_ours_depthpro"
# Depth Anything V2
CUDA_VISIBLE_DEVICES='0' python tool/depth_test.py --dust3r_dynamic_model_path="align3r_depthanything.pth" --align_with_lad --depth_max=70 --depth_prior_name=depthanything --dataset_name=PointOdyssey --eval --output_postfix="results/PointOdyssey_depth_ours_depthanything" # Depth Pro
CUDA_VISIBLE_DEVICES='0' python tool/depth_test.py --dust3r_dynamic_model_path="align3r_depthpro.pth" --align_with_lad --depth_max=70 --depth_prior_name=depthpro --dataset_name=FlyingThings3D --eval --output_postfix="results/FlyingThings3D_depth_ours_depthpro"
# Depth Anything V2
CUDA_VISIBLE_DEVICES='0' python tool/depth_test.py --dust3r_dynamic_model_path="align3r_depthanything.pth" --align_with_lad --depth_max=70 --depth_prior_name=depthanything --dataset_name=FlyingThings3D --eval --output_postfix="results/FlyingThings3D_depth_ours_depthanything" # Depth Pro
CUDA_VISIBLE_DEVICES='0' python tool/depth_test.py --dust3r_dynamic_model_path="align3r_depthpro.pth" --align_with_lad --depth_max=70 --depth_prior_name=depthpro --dataset_name=bonn --eval --output_postfix="results/Bonn_depth_ours_depthpro"
# Depth Anything V2
CUDA_VISIBLE_DEVICES='0' python tool/depth_test.py --dust3r_dynamic_model_path="align3r_depthanything.pth" --align_with_lad --depth_max=70 --depth_prior_name=depthanything --dataset_name=bonn --eval --output_postfix="results/Bonn_depth_ours_depthanything" # Depth Pro
CUDA_VISIBLE_DEVICES='0' python tool/depth_test.py --dust3r_dynamic_model_path="align3r_depthpro.pth" --align_with_lad --depth_max=70 --depth_prior_name=depthpro --dataset_name=tum --eval --output_postfix="results/tum_depth_ours_depthpro"
# Depth Anything V2
CUDA_VISIBLE_DEVICES='0' python tool/depth_test.py --dust3r_dynamic_model_path="align3r_depthanything.pth" --align_with_lad --depth_max=70 --depth_prior_name=depthanything --dataset_name=tum --eval --output_postfix="results/tum_depth_ours_depthanything"We find that the flow loss proposed in MonST3R is crucial for pose estimation, so we have incorporated it into our implementation. We sincerely thank the authors of MonST3R for sharing the code for their outstanding work.
bash pose_test.shPlease change the --dust3r_dynamic_model_path, --output_postfix, --dataset_name, --depth_prior_name.
# Depth Pro
CUDA_VISIBLE_DEVICES='0' python tool/pose_test.py --dust3r_dynamic_model_path="align3r_depthpro.pth" --output_postfix="results/sintel_pose_ours_depthpro" --dataset_name=sintel --depth_prior_name=depthpro --start_frame=0 --interval_frame=3000 --mode=eval_pose --scene_graph_type=swinstride-5-noncyclic
# Depth Anything V2
CUDA_VISIBLE_DEVICES='0' python tool/pose_test.py --dust3r_dynamic_model_path="align3r_depthanything.pth" --output_postfix="results/sintel_pose_ours_depthanything" --dataset_name=sintel --depth_prior_name=depthanything --start_frame=0 --interval_frame=3000 --mode=eval_pose --scene_graph_type=swin-5-noncyclic# Depth Pro
CUDA_VISIBLE_DEVICES='0' python tool/pose_test.py --dust3r_dynamic_model_path="align3r_depthpro.pth" --output_postfix="results/bonn_pose_ours_depthpro" --dataset_name=bonn --depth_prior_name=depthpro --start_frame=0 --interval_frame=30 --mode=eval_pose --scene_graph_type=swin-5-noncyclic
# Depth Anything V2
CUDA_VISIBLE_DEVICES='0' python tool/pose_test.py --dust3r_dynamic_model_path="align3r_depthanything.pth" --output_postfix="results/bonn_pose_ours_depthanything" --dataset_name=bonn --depth_prior_name=depthanything --start_frame=0 --interval_frame=30 --mode=eval_pose --scene_graph_type=swin-5-noncyclic# Depth Pro
CUDA_VISIBLE_DEVICES='0' python tool/pose_test.py --dust3r_dynamic_model_path="align3r_depthpro.pth" --output_postfix="results/tum_pose_ours_depthpro" --dataset_name=tum --depth_prior_name=depthpro --start_frame=0 --interval_frame=30 --mode=eval_pose --scene_graph_type=swin-5-noncyclic
# Depth Anything V2
CUDA_VISIBLE_DEVICES='0' python tool/pose_test.py --dust3r_dynamic_model_path="align3r_depthanything.pth" --output_postfix="results/tum_pose_ours_depthanything" --dataset_name=tum --depth_prior_name=depthanything --start_frame=0 --interval_frame=30 --mode=eval_pose --scene_graph_type=swin-5-noncyclicPlease use the viser to visualize the point cloud results, you can acquire the code from MonST3R. Thanks for their excellent work!
python viser/visualizer_monst3r.py --data path/dataset/video --init_conf --fg_conf_thre 1.0 --no_mask --wxyzIf you find our work useful, please cite:
@article{lu2024align3r,
title={Align3R: Aligned Monocular Depth Estimation for Dynamic Videos},
author={Lu, Jiahao and Huang, Tianyu and Li, Peng and Dou, Zhiyang and Lin, Cheng and Cui, Zhiming and Dong, Zhen and Yeung, Sai-Kit and Wang, Wenping and Liu, Yuan},
journal={arXiv preprint arXiv:2412.03079},
year={2024}
}Our code is based on DUSt3R, MonST3R, Depth Pro, Depth Anything V2 and ControlNet. Our visualization code can acquired from MonST3R. We thank the authors for their excellent work!