The MLflow Regression Recipe is an MLflow Recipe
(previously known as MLflow Pipeline) for developing high-quality regression models.
It is designed for developing models using scikit-learn and frameworks that integrate with scikit-learn,
such as the XGBRegressor API from XGBoost.
This repository is a template for developing production-ready regression models with the MLflow Regression Recipe. It provides a recipe structure for creating models as well as pointers to configurations and code files that should be filled in to produce a working recipe.
Code developed with this template should be run with MLflow Recipes. An example implementation of this template can be found in the Recipe Regression Example repo, which targets the NYC taxi dataset for its training problem.
Note: MLflow Recipes is an experimental feature in MLflow. If you observe any issues, please report them here. For suggestions on improvements, please file a discussion topic here. Your contribution to MLflow Recipes is greatly appreciated by the community!
- Deterministic data splitting
- Reproducible data transformations
- Hyperparameter tuning support
- Model registration for use in production
- Starter code for ingest, split, transform and train steps
- Cards containing step results, including dataset profiles, model leaderboard, performance plots and more
To use this MLflow regression recipe,
simply install the packages listed in the requirements.txt file. Note that Python 3.8 or above is recommended.
pip install requirements.txt
You may need to install additional libraries for extra features:
- Hyperopt is required for hyperparameter tuning.
- PySpark is required for distributed training or to ingest Spark tables.
- Delta is required to ingest Delta tables. These libraries are available natively in the Databricks Runtime for Machine Learning.
After installing MLflow Recipes, you can clone this repository to get started. Simply fill in the required values annotated by FIXME::REQUIRED comments in the Recipe configuration file
and in the appropriate profile configuration: local.yaml
(if running locally) or databricks.yaml
(if running on Databricks).
The Recipe will then be in a runnable state, and when run completely, will produce a trained model ready for batch
scoring, along with cards containing detailed information about the results of each step.
The model will also be registered to the MLflow Model Registry if it meets registration thresholds.
To iterate and improve your model, follow the MLflow Recipes usage guide.
Note that iteration will likely involve filling in the optional FIXMEs in the
step code files with your own code, in addition to the configuration keys.
Once the model under development has reached desired quality, one may programatically run the adapted recipe to either reproduce the model consistently, or train a production model with different input data source (e.g. production dataset) via automated processes such as continuous deployment (CD). Below are recommendations for productionizing a recipe depending on its running environments:
- [Local|CICD] Running the recipe via command line:
mlflow recipes run --profile {PROFILE} - [Databricks] Creating a new notebook (e.g.
notebooks/databricks_prod.py), instantiate and run the entire recipe viar = Recipe(profile=PROFILE); r.run()with desired profile.
Below is a visual overview of the MLflow Regression Recipe's information flow.
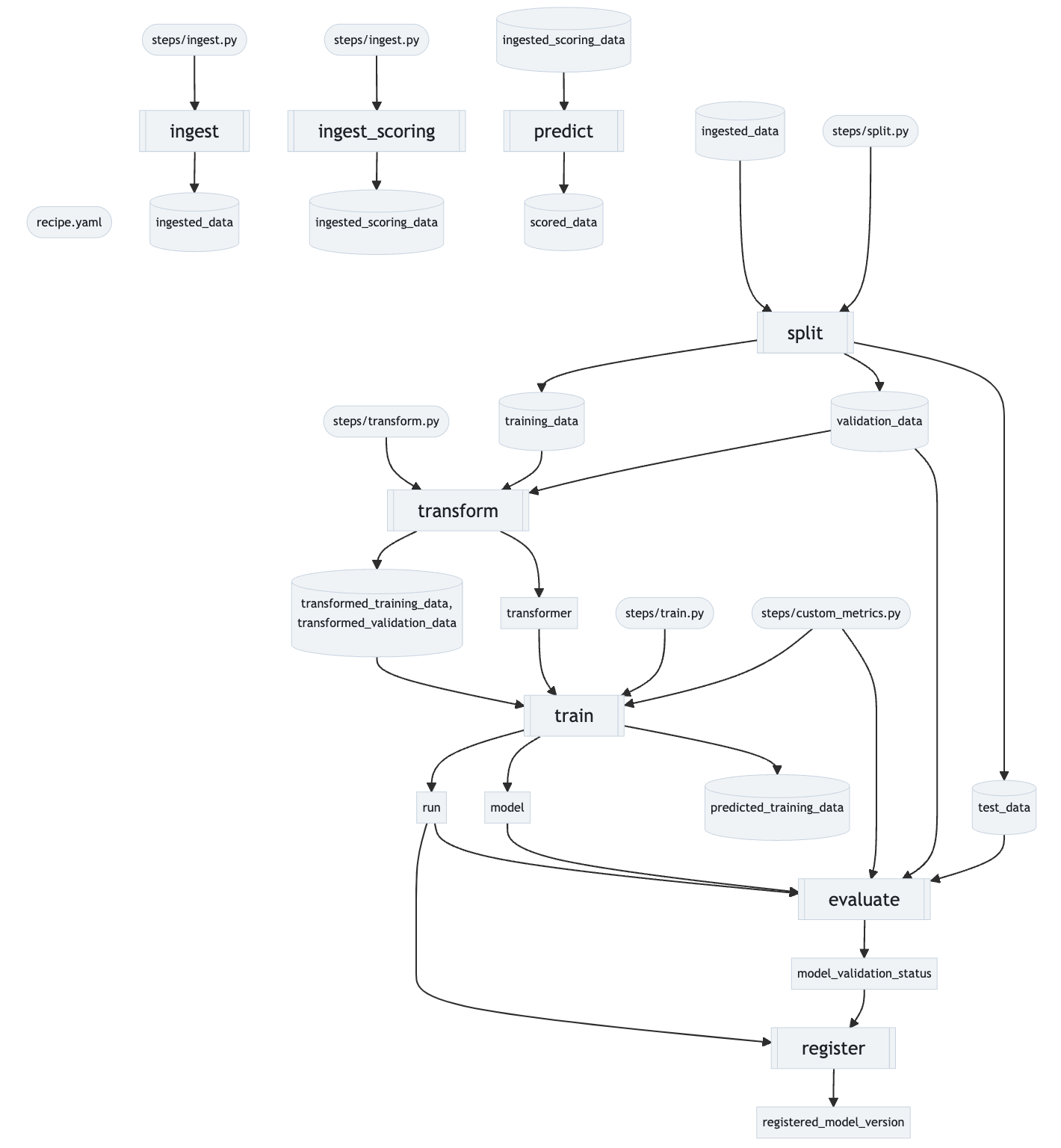
Model develompent consists of the following sequential steps:
ingest -> split -> transform -> train -> evaluate -> register
The batch scoring workflow consists of the following sequential steps:
ingest_scoring -> predict
A detailed reference for each step follows.
Each of the steps in the recipe produces artifacts after completion. These artifacts consist of cards containing
detailed execution information, as well as other step-specific information.
The Recipe.inspect()
API is used to view step cards. The get_artifact
API is used to load all other step artifacts by name.
Per-step artifacts are further detailed in the following step references.
Specifies the name of the column containing targets / labels for model training and evaluation
target_col: string. Required.
The name of the column set as the target for model training. Example:target_col: "fare_amount"
The primary evaluation metric is the one that will be used to select the best performing model in the MLflow UI as
well as in the train and evaluation steps. This can be either a built-in metric or a custom metric (see below).
Models are ranked by this primary metric.
primary_metric: string. Required.
The name of the primary evaluation metric. Example:primary_metric: "root_mean_squared_error"
The ingest step loads the dataset specified by the steps.ingest section in recipe.yaml.
Note: If you make changes to the dataset referenced by the ingest step (e.g. by adding new records or columns),
you must manually re-run the ingest step in order to use the updated dataset in the recipe.
The ingest step does not automatically detect changes in the dataset.
Below are all the possible options and full reference guide for different configurations allowed in the ingest step:
Using: "parquet"
location: string. Required.
Dataset locations on the local filesystem are supported, as well as HTTP(S) URLs and any other remote locations resolvable by MLflow. One may specify multiple data locations by a list of locations as long as they have the same data format (see example below) Examples:location: ./data/sample.parquetlocation: https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2022-01.parquetlocation: ["./data/sample.parquet", "https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2022-01.parquet"]
Example config in recipe.yaml:
steps:
ingest:
using: "parquet"
location: "./data/sample.parquet"
Using: "delta"
-
location: string. Required.
A path pointing to the Delta table location or a catalog path (when running on Databricks) of the format "catalog.schema.table", for more details on the table format, see here Examples:location: catalog.schema.tablelocation: "dbfs:/user/hive/warehouse/ml.db/all_prices_1990_2021_mar" -
version: int. Optional.
Use this to specify the Delta table version to read from. -
timestamp: timestamp. Optional. Use this to specify the timestamp at which to read data.
Example config in recipe.yaml:
steps:
ingest:
using: "delta"
location: "dbfs:/user/hive/warehouse/ml.db/all_prices_1990_2021_mar"
version: 1
Using: "spark_sql"
sql: string. Required.
Specifies a SparkSQL statement that identifies the dataset to use. Either location or sql must be specified Examples:sql: "SELECT * FROM delta.`dbfs:/databricks-datasets/nyctaxi-with-zipcodes/subsampled`"
Example config in recipe.yaml:
steps:
ingest:
using: "spark_sql"
sql: "SELECT * FROM delta.`dbfs:/databricks-datasets/nyctaxi-with-zipcodes/subsampled`"
Using: "custom"
-
location: string. Required.
Dataset locations on the local filesystem are supported, as well as HTTP(S) URLs and any other remote locations resolvable by MLflow. One may specify multiple data locations by a list of locations as long as they have the same data format (see example below) Examples:location: ./data/sample.csvlocation: https://raw.githubusercontent.com/fivethirtyeight/uber-tlc-foil-response/master/uber-trip-data/uber-raw-data-apr14.csvlocation: ["./data/sample.parquet", "https://raw.githubusercontent.com/fivethirtyeight/uber-tlc-foil-response/master/uber-trip-data/uber-raw-data-apr14.csv"] -
loader_method: string.
Method name of the custom loader function fromsteps/ingest.py. The custom loader function allows use of datasets in other formats, such ascsv. The function should be defined insteps/ingest.py, and should accept two parameters:location:str. Path to the dataset file.
It should return a Pandas DataFrame representing the content of the specified file.
steps/ingest.pycontains an example placeholder function.Example:
loader_method: read_csv_as_dataframe
Example config in recipe.yaml:
steps:
ingest:
using: "custom"
location: "./data/sample.csv"
loader_method: read_csv_as_dataframe
Example loader_method function for ingest.py
def read_csv_as_dataframe(location: str) -> DataFrame:
import pandas
return pandas.read_csv(location, index_col=0)Step artifacts:
ingested_data: The ingested data as a Pandas DataFrame.
The split step splits the ingested dataset produced by the ingest step into:
- a training dataset for model training
- a validation dataset for model performance evaluation & tuning, and
- a test dataset for model performance evaluation.
Subsequent steps use these datasets to develop a model and measure its performance.
The post-split method should be written in steps/split.py and should accept three parameters:
train_df: DataFrame. The unprocessed train dataset.validation_df: DataFrame. The unprocessed validation dataset.test_df: DataFrame. The unprocessed test dataset.
It should return a triple representing the processed train, validation and test datasets. steps/split.py contains an example placeholder function.
The split step is configured by the steps.split section in recipe.yaml as follows:
Using: "custom"
-
split_method: string. Required. The user-defined split function should be written in steps/split.py, and should return a Series with each element to be either 'TRAINING', 'VALIDATION' or 'TEST' indicating whether each row should should be part of which split. Example:split_method: custom_split -
post_split_filter_method: string. Optional. Name of the method specified insteps/split.pyused to "post-process" the split datasets.
This procedure is meant for removing/filtering records, or other cleaning processes. Arbitrary data transformations should be done in the transform step.
Example:post_split_filter_method: create_dataset_filterExample config in
recipe.yaml:steps: split: using: custom split_method: custom_split post_split_filter_method: create_dataset_filterExample create_dataset_filter function for
split.pydef custom_split(df): """ Mark rows of the ingested datasets to be split into training, validation, and test datasets. :param dataset: The dataset produced by the data ingestion step. :return: Series of strings with each element to be either 'TRAINING', 'VALIDATION' or 'TEST' """ from pandas import Series splits = Series("TRAINING", index=range(len(df))) # 3rd quarter is validation data splits[df["year"] >= 3] = "VALIDATION" # 4th quarter is testing data splits[df["year"] >= 4] = "TEST" return splits def create_dataset_filter(dataset: DataFrame) -> Series(bool): """ Mark rows of the split datasets to be additionally filtered. This function will be called on the training datasets. :param dataset: The {train,validation,test} dataset produced by the data splitting procedure. :return: A Series indicating whether each row should be filtered """ return ( (dataset["fare_amount"] > 0) & (dataset["trip_distance"] < 400) & (dataset["trip_distance"] > 0) & (dataset["fare_amount"] < 1000) ) | (~dataset.isna().any(axis=1))
Using: "split_ratios"
-
split_ratios: list. Optional. The fraction of records allocated to each dataset is defined by thesplit_ratiosattribute of thesplitstep definition inrecipe.yamlspecifying the ratios by which to split the dataset into training, validation and test sets.
Example:split_ratios: [0.75, 0.125, 0.125] # Defaults to this ratio if unspecified -
post_split_filter_method: string. Optional. Name of the method specified insteps/split.pyused to "post-process" the split datasets.
This procedure is meant for removing/filtering records, or other cleaning processes. Arbitrary data transformations should be done in the transform step.
Example:post_split_filter_method: create_dataset_filterExample config in
recipe.yaml:steps: split: using: split_ratios split_ratios: [0.75, 0.125, 0.125] post_split_filter_method: create_dataset_filterExample create_dataset_filter function for
split.pydef create_dataset_filter(dataset: DataFrame) -> Series(bool): """ Mark rows of the split datasets to be additionally filtered. This function will be called on the training, validation, and test datasets. :param dataset: The {train,validation,test} dataset produced by the data splitting procedure. :return: A Series indicating whether each row should be filtered """ return ( (dataset["fare_amount"] > 0) & (dataset["trip_distance"] < 400) & (dataset["trip_distance"] > 0) & (dataset["fare_amount"] < 1000) ) | (~dataset.isna().any(axis=1))
Step artifacts:
training_data: the training dataset as a Pandas DataFrame.validation_data: the validation dataset as a Pandas DataFrame.test_data: the test dataset as a Pandas DataFrame.
The transform step uses the training dataset created by the split step to fit a transformer that performs the user-defined transformations. The transformer is then applied to the training dataset and the validation dataset, creating transformed datasets that are used by subsequent steps for estimator training and model performance evaluation.
The transform step is configured by the steps.transform section in recipe.yaml:
Note: The steps.transform section is not required. If absent, an identity transformer will be used.
Below are all the possible options and full reference guide for different configurations allowed in the transform step:
Using: "custom"
-
transformer_method: string. Optional.
The user-defined function should be written insteps/transform.py, and should return an unfitted estimator that is sklearn-compatible; that is, the returned object should definefit()andtransform()methods.steps/transform.pycontains an example placeholder function. The config mentions the name of the method specified insteps/transform.py. If absent, an identity transformer with will be used. Example:transformer_method: transformer_fnExample config in
recipe.yaml:steps: transform: using: "custom" transformer_method: transformer_fnExample transformer_fn function for
transform.pydef transformer_fn(location: str) -> DataFrame: from sklearn.preprocessing import StandardScaler return Pipeline( steps=[ ( "scale_features", StandardScaler(), ) ] )
Step artifacts:
transformed_training_data: transformed training dataset as a Pandas DataFrame.transformed_validation_data: transformed validation dataset as a Pandas DataFrame.transformer: the sklearn transformer.
The train step uses the transformed training dataset output from the transform step to fit an AutoML or user-defined estimator. The estimator is then joined with the fitted transformer output from the transform step to create a model recipe. Finally, this model recipe is evaluated against the transformed training and validation datasets to compute performance metrics.
Custom evaluation metrics are computed according to definitions in steps/custom_metrics.py
and the metrics section of recipe.yaml; see Custom Metrics section for reference.
Hyper-parameter tuning during the train step can also be enabled as a step config in the steps.train section in recipe.yaml.
The model recipe and its associated parameters, performance metrics, and lineage information are logged to MLflow Tracking, producing an MLflow Run.
The train step is configured by the steps.train section in recipe.yaml.
Below are all the possible options and full reference guide for different configurations allowed in the train step:
Using: "automl/flaml"
-
time_budget_secs: float. Optional.
A float number of the time budget in seconds. Default to 600 seconds. -
flaml_params: Dict. Optional.
Any additional parameters to pass along to FLAML.
Example config in recipe.yaml:
steps:
train:
using: "automl/flaml"
time_budget_secs: 3000
Using: "custom"
-
estimator_method: string. Required. The user-defined estimator function should be written insteps/train.py, and should return an unfitted estimator that issklearn-compatible; that is, the returned object should definefit()andtransform()methods.steps/train.pycontains an example placeholder function. The config mentions the name of the method specified insteps/train.py.Example:
estimator_method: estimator_fn -
estimator_params: dict. Optional. Defaults toNoneA dictionary of estimator params that are hardcoded and passed to the training function to train the model -
Tuning configuration reference
-
enabled: boolean. Required.
Indicates whether or not tuning is enabled. -
max_trials: int. Required.
Max tuning trials to run. -
algorithm: string. Optional.
Indicates whether or not tuning is enabled. -
early_stop_fn: string. Optional.
Early stopping function to be passed tohyperopt. -
parallelism: int. Optional.
Number of workers to runhyperoptacross. -
sample_fraction: float. Optional.
Sampling fraction in the range(0, 1.0]to indicate the amount of data used in tuning. -
parameters: list. Required.
hyperoptsearch space in yaml format. Full spec on parameters can be found here
-
Example config in recipe.yaml:
steps:
train:
using: "custom"
estimator_method: estimator_fn
estimator_params:
depth: 3
tuning:
enabled: True
algorithm: "hyperopt.rand.suggest"
max_trials: 5
early_stop_fn: my_early_stop_fn
parallelism: 1
sample_fraction: 0.5
parameters:
alpha:
distribution: "uniform"
low: 0.0
high: 0.01
penalty:
values: ["l1", "l2", "elasticnet"]
Example estimator_fn function for train.py
from typing import Dict, Any
def estimator_fn(estimator_params: Dict[str, Any] = None):
from sklearn.linear_model import SGDRegressor
return SGDRegressor(random_state=42, **estimator_params)
def my_early_stop_fn(*args):
from hyperopt.early_stop import no_progress_loss
return no_progress_loss(10)(*args)Step artifacts:
model: the MLflow Model recipe created in the train step as a PyFuncModel instance.
The evaluate step evaluates the model recipe created by the train step on the test dataset output from the split step, computing performance metrics and model explanations.
Performance metrics are compared against configured thresholds to produce a model_validation_status, which indicates
whether or not a model is validated to be registered to the MLflow Model Registry
by the subsequent register step.
These model performance thresholds are defined in the
validation_criteria section of the evaluate step definition in recipe.yaml.
Custom evaluation metrics are computed according to definitions in steps/custom_metrics.py
and the metrics section of recipe.yaml; see the custom metrics section for reference.
Model performance metrics and explanations are logged to the same MLflow Tracking Run used by the train step.
The evaluate step is configured by the steps.evaluate section in recipe.yaml:
Full configuration reference
validation_criteria: list. Optional.
A list of validation thresholds, each of which a trained model must meet in order to be eligible for registration in the register step. A definition for a validation threshold consists of a metric name (either a built-in metric or a custom metric), and a threshold value.
Example:validation_critera: - metric: root_mean_squared_error threshold: 10
Step artifacts:
run: the MLflow Tracking Run containing the model recipe, as well as performance and metrics created during the train and evaluate steps.
The register step checks the model_validation_status output of the preceding evaluate step and,
if model validation was successful (if model_validation_status is 'VALIDATED'), registers the model recipe created
by the train step to the MLflow Model Registry. If the model_validation_status does not indicate that the model
passed validation checks (if model_validation_status is 'REJECTED'), the model recipe is not registered to the
MLflow Model Registry.
If the model recipe is registered to the MLflow Model Registry, a registered_model_version is produced containing
the model name and the model version.
The register step is configured by the steps.register section in recipe.yaml:
Full configuration reference
allow_non_validated_model: boolean. Required.
Whether to allow registration of models that fail to meet performance thresholds.
Step artifacts:
registered_model_version: the MLflow Model Registry ModelVersion registered in this step.
After model training, the regression recipe provides the capability to score data with the
trained model. This is convenient for scoring a static dataset, e.g., the test set from a Kaggle competition.
For more advanced ETL workflows for scoring, we recommend using spark_udf directly instead, because it is more flexible to handle different data scenarios.
The ingest scoring step, defined in the steps.ingest_scoring section in recipe.yaml,
specifies the dataset used for batch scoring and has the same API as the ingest step.
Step artifacts:
ingested_scoring_data: the ingested scoring data as a Pandas DataFrame.
The predict step uses the model registered by the register step to score the
ingested dataset produced by the ingest scoring step and writes the resulting
dataset to the specified output format and location. To fix a specific model for use in the predict
step, provide its model URI as the model_uri attribute of the recipe.yaml predict step definition.
The predict step is configured by the steps.predict section in recipe.yaml:
Full configuration reference
-
output: string. Required. Specifies where the output of the predict step is logged.-
using: string. Required.
Specifies the output format of the scored data from the predict step. One ofparquet,delta, andtable. Theparquetformat writes the scored data as parquet files under a specified path. Thedeltaformat writes the scored data as a delta table under a specified path. Thetableformat writes the scored data as delta table and creates a metastore entry for this table with a specified name. -
location: string. Required.
For theparquetanddeltaoutput formats, this attribute specifies the output path for writing the scored data. In Databricks, this path will be written to be under DBFS, e.g. the pathmy/special/pathwill be written under/dbfs/my/special/path. For thetableoutput format, this attribute specifies the table name that is used to create the metastore entry for the written delta table. Example:location: ./outputs/predictions
-
-
model_uri: string. Optional.
Specifies the URI of the model to use for batch scoring. If empty, the latest model version produced by the register step is used. If the register step was cleared, the latest version of the registered model specified by themodel_nameattribute of therecipe.yamlModel Registry configuration will be used.
Example:model_uri: models/model.pkl -
result_type: string. Optional. Defaults todouble.
Specifies the data type for predictions generated by the model. See the MLflow spark_udf API docs for more information. -
save_mode: string. Optional. Defaults tooverwrite.
Specifies the save mode used by Spark for writing the scored data. See the PySpark save modes documentation for more information.
Step artifacts:
scored_data: the scored dataset, with model predictions under thepredictioncolumn, as a Pandas DataFrame.
The MLflow Tracking server can be configured to log MLflow runs to a specific server. Tracking information is specified
in the profile configuration files - profiles/local.yaml
if running locally and profiles/databricks.yaml
if running on Databricks.
Configuring a tracking server is optional. If this configuration is absent, the default experiment will be used.
Tracking information is configured with the experiment section in the profile configuration:
Full configuration reference
-
name: string. Required, if configuring tracking.
Name of the experiment to log MLflow runs to. -
tracking_uri: string. Required, if configuring tracking.
URI of the MLflow tracking server to log runs to. Alternatively, theMLFLOW_TRACKING_URIenvironment variable can be set to point to a valid tracking server. -
artifact_location: string. Optional. URI of the location to log run artifacts to.
Example experiment config in profile.yaml
experiment:
name: "experiment-name"
tracking_uri: "sqlite:///metadata/mlflow/mlruns.db"
artifact_location: "./metadata/mlflow/mlartifacts"
To register trained models to the MLflow Model Registry, further configuration may be required. If unspecified, models will be logged to the same server as specified in the tracking URI.
To register models to a different server, specify the desired server in the model_registry section in the profile configuration:
Full configuration reference
-
registry_uri: string. Required, if this section is present.
URI of the model registry server to which to register trained models. -
model_name: string. Required.
Specifies the name to use when registering the trained model to the model registry.
Example experiment config in profile.yaml
model_registry:
registry_uri: "sqlite:///metadata/mlflow/registry.db"
model_name: "model-name"
Evaluation metrics calculate model performance against different datasets. The metrics defined in the recipe will be calculated as part of the training and evaluation steps, and calculated values will be recorded in each step’s information card.
This regression recipe features a set of built-in metrics, and supports user-defined metrics as well.
Metrics are configured under the custom_metrics section of recipe.yaml, according to the following specification:
Full configuration reference
custom_metrics: string. Optional.
A list of custom metric configurations.
Note that each metric specifies a boolean value greater_is_better, which indicates whether a higher value for that
metric is associated with better model performance.
The following metrics are built-in. Note that greater_is_better = False for all these metrics:
mean_absolute_errormean_squared_errorroot_mean_squared_errormax_errormean_absolute_percentage_error
Custom evaluation metrics define how trained models should be evaluated against custom criteria not captured by
built-in sklearn evaluation metrics.
Custom evaluation metric functions should be defined in steps/custom_metrics.py. Function to define the custom_metrics should adhere to the following signature.
Custom metrics are specified as a list under the metrics.custom key in recipe.yaml, specified as follows:
-
name: string. Required.
Name of the custom metric. This will be the name by which you refer to this metric when including it in model evaluation or model training. -
function: string. Required. Specifies the function this custom metric refers to. -
greater_is_better: boolean. Required. Boolean indicating whether a higher metric value indicates better model performance.
An example custom metric configuration is as follows:
custom_metrics:
- name: weighted_mean_square_error
function: get_custom_metrics
greater_is_better: True