This repo covers Kubernetes objects' and components' details (Kubectl, Pod, Deployment, Service, ConfigMap, Volume, PV, PVC, Daemonset, Secret, Affinity, Taint-Toleration, Helm, etc.), and possible example usage scenarios (HowTo: Hands-on LAB) in a nutshell.
- Have a knowledge of Container Technology (Docker). You can learn it from here => Fast-Docker
Keywords: Containerization, Kubernetes, Kubectl, Pod, Deployment, Service, ConfigMap, ReplicaSet, Volume, Cheatsheet.
Note: K8s objects and objects feature can be updated/changed in time. While creating this repo, the version of K8s was v1.22.3. Some sections are trying to be kept up to date. Especially Creating K8s Cluster with Kubeadm and Containerd.
- LAB: K8s Creating Pod - Imperative Way
- LAB: K8s Creating Pod - Declarative Way (With File) - Environment Variable
- LAB: K8s Multicontainer - Sidecar - Emptydir Volume - Port-Forwarding
- LAB: K8s Deployment - Scale Up/Down - Bash Connection - Port Forwarding
- LAB: K8s Rollout - Rollback
- LAB: K8s Service Implementations (ClusterIp, NodePort and LoadBalancer)
- LAB: K8s Liveness Probe
- LAB: K8s Secret (Declarative and Imperative Way)
- LAB: K8s Config Map
- LAB: K8s Node Affinity
- LAB: K8s Taint-Toleration
- LAB: K8s Daemonset - Creating 3 nodes on Minikube
- LAB: K8s Persistent Volume and Persistent Volume Claim
- LAB: K8s Stateful Sets - Nginx
- LAB: K8s Job
- LAB: K8s Cron Job
- LAB: K8s Ingress
- LAB: Helm Install & Usage
- LAB: K8s Cluster Setup with Kubeadm and Containerd
- LAB: K8s Cluster Setup with Kubeadm and Docker
- LAB: Helm-Jenkins on running K8s Cluster (2 Node Multipass VM)
- LAB: Enable Dashboard on Real K8s Cluster
- LAB: K8s Monitoring - Prometheus and Grafana
- Kubectl Commands Cheatsheet
- Helm Commands Cheatsheet
- Motivation
- What is Kubernetes?
- Kubernetes Architecture
- Kubernetes Components
- Installation
- Kubectl Config – Usage
- Pod: Creating, Yaml, LifeCycle
- MultiContainer Pod, Init Container
- Label and Selector, Annotation, Namespace
- Deployment
- Replicaset
- Rollout and Rollback
- Network, Service
- Liveness and Readiness Probe
- Resource Limit, Environment Variable
- Volume
- Secret
- ConfigMap
- Node – Pod Affinity
- Taint and Toleration
- Deamon Set
- Persistent Volume and Persistent Volume Claim
- Storage Class
- Stateful Set
- Job, CronJob
- Authentication, Role Based Access Control, Service Account
- Ingress
- Dashboard
- Play With Kubernetes
- Helm: Kuberbetes Package Manager
- Kubernetes Commands Cheatsheet
- Helm Commands Cheatsheet
- Kubernetes Cluster Setup: Kubeadm, Containerd, Multipass
- Monitoring Kubernetes Cluster with SSH, Prometheus and Grafana
- Other Useful Resources Related Kubernetes
- References
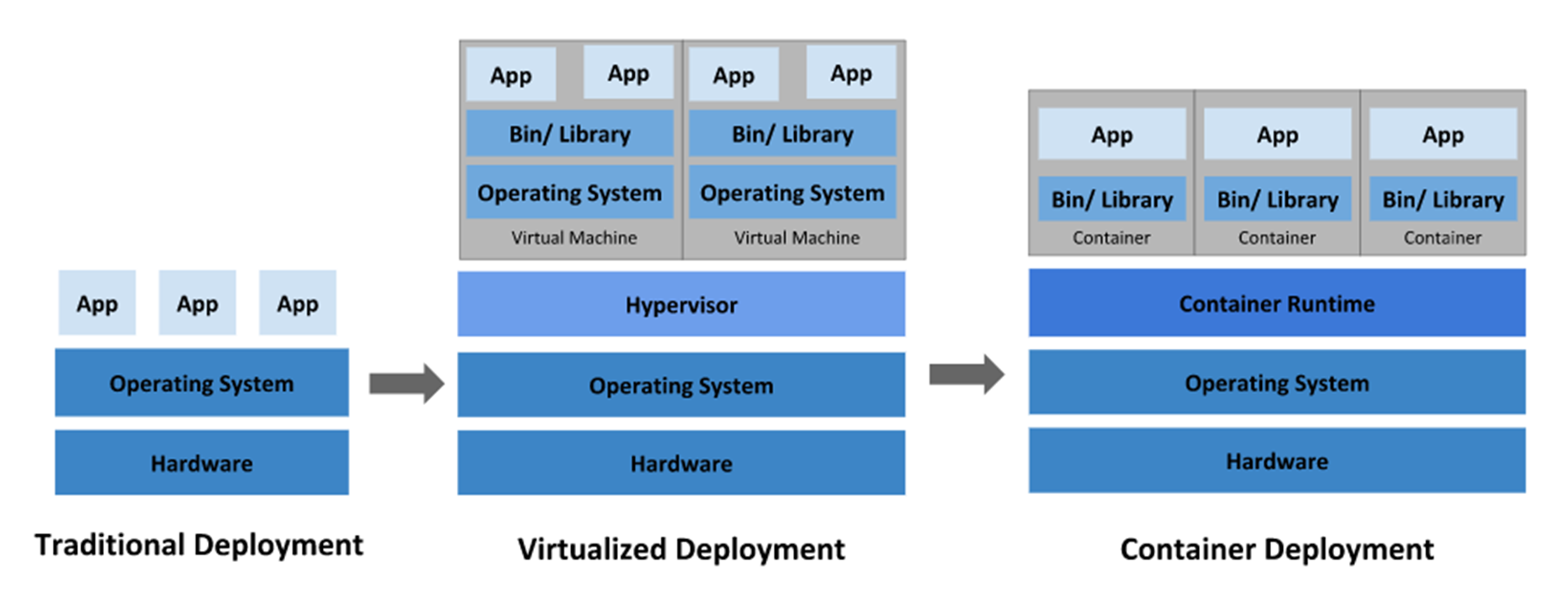
Why should we use Kubernetes? "Kubernetes is a portable, extensible, open-source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation. It has a large, rapidly growing ecosystem. Kubernetes services, support, and tools are widely available." (Ref: Kubernetes.io)
- "Containerization is an operating system-level virtualization or application-level virtualization over multiple network resources so that software applications can run in isolated user spaces called containers in any cloud or non-cloud environment" (wikipedia)
- With Docker Environment, we can create containers.
- Kubernetes and Docker Swarm are the container orchestration and management tools that automate and schedule the deployment, management, scaling, and networking of containers.

- Service discovery and load balancing: Kubernetes can expose a container using the DNS name or using their own IP address. If traffic to a container is high, Kubernetes is able to load balance and distribute the network traffic so that the deployment is stable.
- Storage orchestration: Kubernetes allows you to automatically mount a storage system of your choice, such as local storages, public cloud providers, and more.
- Automated rollouts and rollbacks: You can describe the desired state for your deployed containers using Kubernetes, and it can change the actual state to the desired state at a controlled rate.
- Automatic bin packing: You tell Kubernetes how much CPU and memory (RAM) each container needs. Kubernetes can fit containers onto your nodes to make the best use of your resources.
- Self-monitoring: Kubernetes checks constantly the health of nodes and containers
- Self-healing: Kubernetes restarts containers that fail, replaces containers, kills containers that don't respond to your user-defined health check
- Automates various manual processes: for instance, Kubernetes will control for you which server will host the container, how it will be launched etc.
- Interacts with several groups of containers: Kubernetes is able to manage more cluster at the same time
- Provides additional services: as well as the management of containers, Kubernetes offers security, networking and storage services
- Horizontal scaling: Kubernetes allows you scaling resources not only vertically but also horizontally, easily and quickly
- Container balancing: Kubernetes always knows where to place containers, by calculating the “best location” for them
- Run everywhere: Kubernetes is an open source tool and gives you the freedom to take advantage of on-premises, hybrid, or public cloud infrastructure, letting you move workloads to anywhere you want
- Secret and configuration management: Kubernetes lets you store and manage sensitive information
- "Kubernetes is a portable, extensible, open-source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation. It has a large, rapidly growing ecosystem. Kubernetes services, support, and tools are widely available." (Ref: Kubernetes.io)
 (Ref: Kubernetes.io)
(Ref: Kubernetes.io)
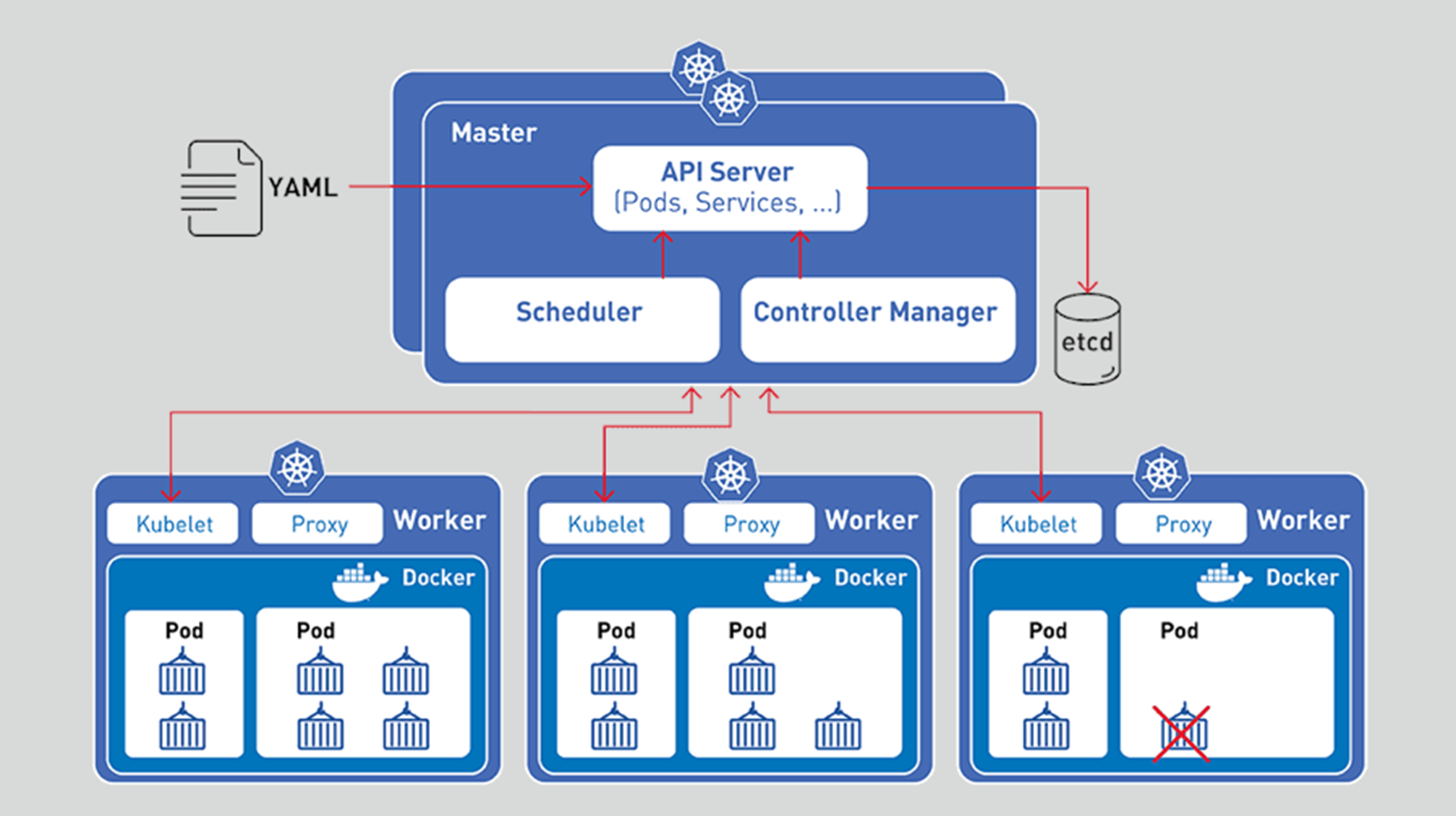
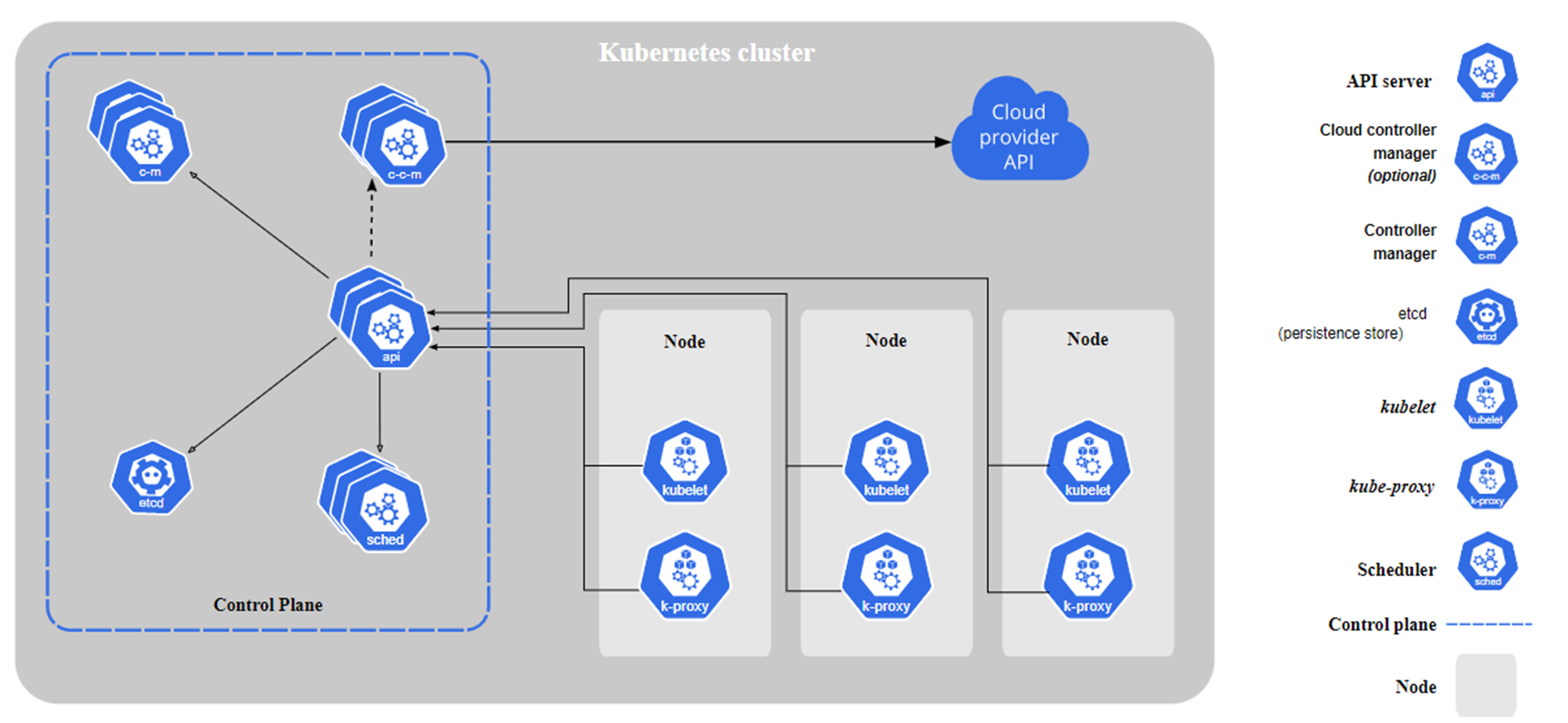
- Control Plane: User enters commands and configuration files from control plane. It controls all cluster.
- API Server: "It exposes the Kubernetes API. The API server is the front end for the Kubernetes control plane."
- Etcd: "Consistent and highly-available key value store used as Kubernetes' backing store for all cluster data (meta data, objects, etc.)."
- Scheduler: "It watches for newly created Pods with no assigned node, and selects a node for them to run on.
- Factors taken into account for scheduling decisions include:
- individual and collective resource requirements,
- hardware/software/policy constraints,
- affinity and anti-affinity specifications,
- data locality,
- inter-workload interference,
- deadlines."
- Factors taken into account for scheduling decisions include:
- Controller Manager: "It runs controller processes.
- Logically, each controller is a separate process, but to reduce complexity, they are all compiled into a single binary and run in a single process.
- Some types of these controllers are:
- Node controller: Responsible for noticing and responding when nodes go down.
- Job controller: Watches for Job objects that represent one-off tasks, then creates Pods to run those tasks to completion.
- Endpoints controller: Populates the Endpoints object (that is, joins Services & Pods).
- Service Account & Token controllers: Create default accounts and API access tokens for new namespaces"
- Cloud Controller Manager: "It embeds cloud-specific control logic. The cloud controller manager lets you link your cluster into your cloud provider's API, and separates out the components that interact with that cloud platform from components that only interact with your cluster. The cloud-controller-manager only runs controllers that are specific to your cloud provider
- The following controllers can have cloud provider dependencies:
- Node controller: For checking the cloud provider to determine if a node has been deleted in the cloud after it stops responding
- Route controller: For setting up routes in the underlying cloud infrastructure
- Service controller: For creating, updating and deleting cloud provider load balancers."
- The following controllers can have cloud provider dependencies:
- Node: "Node components run on every node, maintaining running pods and providing the Kubernetes runtime environment."
- Kubelet: "An agent that runs on each node in the cluster. It makes sure that containers are running in a Pod. The kubelet takes a set of PodSpecs that are provided through various mechanisms and ensures that the containers described in those PodSpecs are running and healthy."
- Kube-proxy: "It is a network proxy that runs on each node in your cluster, implementing part of the Kubernetes Service concept.
- It maintains network rules on nodes. These network rules allow network communication to your Pods from network sessions inside or outside of your cluster.
- It uses the operating system packet filtering layer if there is one and it's available. Otherwise, kube-proxy forwards the traffic itself."
- Container Runtime: "The container runtime is the software that is responsible for running containers.
- Kubernetes supports several container runtimes: Docker, containerd, CRI-O, and any implementation of the Kubernetes CRI (Container Runtime Interface)"
Download:
- Kubectl: The Kubernetes command-line tool, kubectl, allows you to run commands against Kubernetes clusters.
- Minikube: It is a tool that lets you run Kubernetes locally. It runs a single-node Kubernetes cluster on your personal computer (https://minikube.sigs.k8s.io/docs/start/)
- KubeAdm: You can use the kubeadm tool to create and manage Kubernetes clusters. This is for creating cluster with computers (Goto: LAB: K8s Kubeadm Cluster Setup).
from here=> https://kubernetes.io/docs/tasks/tools/
For learning K8s and running on a computer, Kubectl and Minikube are enough to install.
PS: Cloud providers (Azure, Google Cloud, AWS) offer managed K8s (control plane is managed by cloud provides). You can easily create your cluster (number of computer and details) and make connection with Kubectl (using CLI get-credentials of cluster on the cloud)
- You can communicate with K8s cluster in different ways: REST API, Command Line Tool (CLI-Kubectl), GUI (kube-dashboard, etc.)
- After installation, you can find the kubernetes config file (C:\Users\User.kube\config) that is YAML file.
- Config file contains 3 main parts: Clusters (cluster certificate data, server, name), Context (cluster and user, namespace), Users (name, config features, certificates, etc.)
- Kubectl is our main command line tool that connects minikube. There are many combination of commands. So it is not possible to list all commands.
- When run "kubectl" on the terminal, it can be seen some simple commands. Also "kubectl --help" gives more information.
- Pattern: kubectl [get|delete|edit|apply] [pods|deployment|services] [podName|serviceName|deploymentName]
- Example: "kubectl get pods podName", "kubectl delete pods test_pod", "kubectl describe pods firstpod", etc.
- All necessary/most usable commands are listed in the "Kubernetes Commands Cheatsheet". Please have a look to get more information and usage.
- Pod is the smallest unit that is created and managed in K8s.
- Pods may contain more than 1 container, but mostly pods contain only 1 container.
- Each pod has unique id (uid).
- Each pod has unique IP address.
- Containers in the same Pod run on the same Node (computer), and these containers can communicate with each other on the localhost.
- Creation of the first pod, IMPERATIVE WAY (with command):
- Please have a look Scenario (Creating Pod - Imperative way, below link) to learn more information about the pod's kubectl commands.
- how to create basic K8s pod using imperative commands,
- how to get more information about pod (to solve troubleshooting),
- how to run commands in pod,
- how to delete pod.
Goto the Scenario: LAB: K8s Creating Pod - Imperative Way
- Imperative way could be difficult to store and manage process. Every time we have to enter commands. To prevent this, we can use YAML file to define pods and pods' feature. This way is called "Declarative Way".
- Declarative way (with file), Imperative way (with command)
- Sample Yaml File:
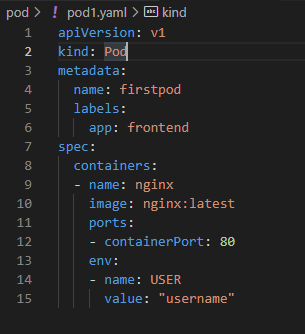
- Please have a look Scenario (Creating Pod - Declarative way, below link) to learn more information.
Goto the Scenario: LAB: K8s Creating Pod - Declarative Way (With File) - Environment Variable
- Pending: API->etcd, pod created, pod id created, but not running on the node.
- Creating: Scheduler take pod from etcd, assing on node. Kubelet on the Node pull images from docker registry or repository.
- ImagePullBackOff: Kubelet can not pull image from registry. E.g. Image name is fault (typo error), Authorization Failure, Username/Pass error.
- Running:
- Container closes in 3 ways:
- App completes the mission and closes automatically without giving error,
- Use or System sends close signal and closes automatically without giving error,
- Giving error, collapsed and closes with giving error code.
- Restart Policies (it can defined in the pod definition):
- Always: Default value, kubelet starts always when closing with or without error,
- On-failure: It starts again when it gets only error,
- Never: It never restarts in any case.
- Container closes in 3 ways:
- Successed (completed): If the container closes successfully without error and restart policy is configured as on-failure/never, it converts to succeed.
- Failed
- CrashLoopBackOff:
- If restart policy is configured as always and container closes again and again, container restarts again and again (Restart waiting duration before restarting again: 10 sec -> 20 sec -> 40 sec -> .. -> 5mins), It runs every 5 mins if the pod is crashed.
- If container runs more than 10 mins, status converted from 'CrashLoopBackOff' to 'Running'.
- Best Practice: 1 Container runs in 1 Pod normally, because the smallest element in K8s is Pod (Pod can be scaled up/down).
- Multicontainers run in the same Pod when containers are dependent of each other.
- Multicontainers in one Pod have following features:
- Multi containers that run on the same Pod run on the same Node.
- Containers in the same Pod run/pause/deleted at the same time.
- Containers in the same Pod communicate with each other on localhost, there is not any network isolation.
- Containers in the same Pod use one volume commonly and they can reach same files in the volume.
- Init containers are used for configuration of apps before running app container.
- Init containers handle what it should run, then it closes successfully, after init containers close, app containers start.
- Example below shows how to define init containers in one Pod. There are 2 containers: appcontainer and initcontainer. Initcontainer is polling the service (myservice). When it finds, it closes and app container starts.
apiVersion: v1
kind: Pod
metadata:
name: initcontainerpod
spec:
containers:
- name: appcontainer # after initcontainer closed successfully, appcontainer starts.
image: busybox
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: initcontainer
image: busybox # init container starts firstly and look up myservice is up or not in every 2 seconds, if there is myservice available, initcontainer closes.
command: ['sh', '-c', "until nslookup myservice; do echo waiting for myservice; sleep 2; done"]# save as service.yaml and run after pod creation
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376- Please have a look Scenario (below link) to learn more information.
Goto the Scenario: LAB: K8s Multicontainer - Sidecar - Emptydir Volume - Port-Forwarding
- Label is important to reach the K8s objects with key:value pairs.
- key:value is used for labels. E.g. tier:frontend, stage:test, name:app1, team:development
- prefix may also be used for optional with key:value. E.g. example.com/tier:front-end, kubernetes.io/ , k8s.io/
- In the file (declerative way), labels are added under metadata. It is possible to add multiple labels.
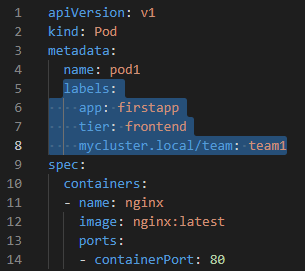
- In the command (imperative way), we can also add label to the pods.
kubectl label pods pod1 team=development #adding label team=development on pod1
kubectl get pods --show-labels
kubectl label pods pod1 team- #remove team (key:value) from pod1
kubectl label --overwrite pods pod1 team=test #overwrite/change label on pod1
kubectl label pods --all foo=bar # add label foo=bar for all pods- We can select/filter pods with kubectl.
kubectl get pods -l "app=firstapp" --show-labels
kubectl get pods -l "app=firstapp,tier=frontend" --show-labels
kubectl get pods -l "app=firstapp,tier!=frontend" --show-labels
kubectl get pods -l "app,tier=frontend" --show-labels #equality-based selector
kubectl get pods -l "app in (firstapp)" --show-labels #set-based selector
kubectl get pods -l "app not in (firstapp)" --show-labels #set-based selector
kubectl get pods -l "app=firstapp,app=secondapp" --show-labels # comma means and => firstapp and secondapp
kubectl get pods -l "app in (firstapp,secondapp)" --show-labels # it means or => firstapp or secondapp- With Node Selector, we can specify which pod run on which Node.
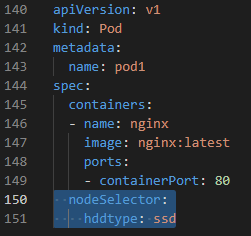
- It is also possible to label nodes with imperative way.
kubectl apply -f podnode.yaml
kubectl get pods -w #always watch
kubectl label nodes minikube hddtype=ssd #after labelling node, pod11 configuration can run, because node is labelled with hddtype:ssd - It is similar to label, but it is used for the detailed information (e.g. owner, notification-email, releasedate, etc.) that are not used for linking objects.
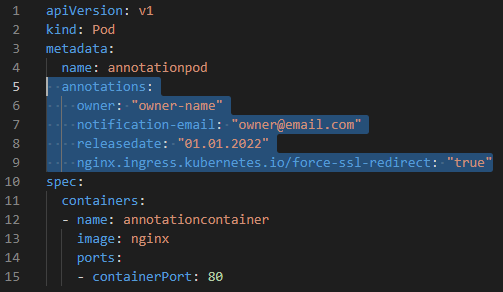
kubectl apply -f podannotation.yaml
kubectl describe pod annotationpod
kubectl annotate pods annotationpod foo=bar #imperative way
kubectl delete -f podannotation.yaml- Namespaces provides a mechanism for isolating groups of resources within a single cluster. They provide a scope for names.
- Namespaces cannot be nested inside one another and each Kubernetes resource can only be in one namespace.
- Kubectl commands run in default namespaces if it is not determined in the command.
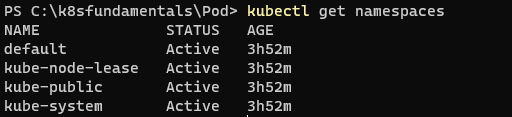
kubectl get pods --namespaces kube-system # get all pods in the kube-system namespaces
kubectl get pods --all-namespaces # get pods from all namespaces
kubectl create namespace development # create new development namespace in imperative way
kubectl get pods -n development # get pods from the development namespace- In declerative way, it is possible to create namespaces and run pod on the related namespace.
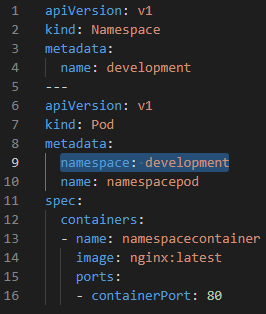
kubectl apply -f namespace.yaml
kubectl get pods -n development #get pods in the development namespace
kubectl exec -it namespacedpod -n development -- /bin/sh #run namespacepod in development namespace- We can avoid to use -n for all command with changing of default namespace (because, if we don't use -n namespace, kubectl commands run on the default namespace).
kubectl config set-context --current --namespace=development #now default namespace is development
kubectl get pods #returns pods in the development namespace
kubectl config set-context --current --namespace=default #now namespace is default
kubectl delete namespaces development #delete development namespace- A Deployment provides declarative updates for Pods and ReplicaSets.
- We define states in the deployment, deployment controller compares desired state and take necessary actions to keep desire state.
- Deployment object is the higher level K8s object that controls and keeps state of single or multiple pods automatically.
- Imperative way:
kubectl create deployment firstdeployment --image=nginx:latest --replicas=2
kubectl get deployments
kubectl get pods -w #on another terminal
kubectl delete pods <oneofthepodname> #we can see another terminal, new pod will be created (to keep 2 replicas)
kubectl scale deployments firstdeployment --replicas=5
kubectl delete deployments firstdeployment- Please have a look Scenario (below link) to learn more about the deployment and declarative way of creating deployment.
Goto the Scenario: LAB: K8s Deployment - Scale Up/Down - Bash Connection - Port Forwarding
- Deployment object create Replicaset object. Deployment provides the transition of the different replicaset automatically.
- Replicaset is responsible for the management of replica creation and remove. But, when the pods are updated (e.g. image changed), it can not update replicaset pods. However, deployment can update for all change. So, best practice is to use deployment, not to use replicaset directly.
- Important: It can be possible to create replicaset directly, but we could not use rollout/rollback, undo features with replicaset. Deployment provide to use rollout/rollback, undo features.
- Rollout and Rollback enable to update and return back containers that run under the deployment.
- 2 strategy for rollout:
- Recreate Strategy: Delete all pods first and create Pods from scratch. If two different versions of SW affect each other negatively, this strategy could be used.
- RollingUpdate Strategy (default): It updates pods step by step. Pods are updated step by step, all pods are not deleted at the same time.
- maxUnavailable: At the update duration, it shows the max number of deleted containers (total:10 containers; if maxUn:2, min:8 containers run in that time period)
- maxSurge: At the update duration, it shows that the max number of containers run on the cluster (total:10 containers; if maxSurge:2, max:12 containers run in a time)
kubectl set image deployment rolldeployment nginx=httpd:alpine --record # change image of deployment
kubectl rollout history deployment rolldeployment #shows record/history revisions
kubectl rollout history deployment rolldeployment --revision=2 #select the details of the one of the revisions
kubectl rollout undo deployment rolldeployment #returns back to previous deployment revision
kubectl rollout undo deployment rolldeployment --to-revision=1 #returns back to the selected revision=1
kubectl rollout status deployment rolldeployment -w #show live status of the rollout deployment
kubectl rollout pause deployment rolldeployment #pause the rollout while updating pods
kubectl rollout resume deployment rolldeployment #resume the rollout if rollout pausedGoto the Scenario: LAB: K8s Rollout - Rollback
- Each pod has unique and own IP address (Containers within a pod share network namespaces).
- All PODs can communicate with all other pods without NAT (Network Address Translation)
- All NODEs can communicate with all pods without NAT.
- The IP of the POD is same throughout the cluster.
- Networking of containers and nodes with different vendors and devices is difficult to handle. So K8s give this responsibility to CNI plugins to handle networking requirements.
- "CNI (Container Network Interface), a Cloud Native Computing Foundation project, consists of a specification and libraries for writing plugins to configure network interfaces in Linux containers, along with a number of supported plugins." => https://github.com/containernetworking/cni
- K8s has CNI plugins that are selected by the users. Some of the CNI methods are: Flannel, calico, weave, and canal.
- Calico (https://github.com/projectcalico/calico) is the one of the popular and open source CNI method/plugin in K8s.
- Network Management in the cluster:
- IP assignments to Pods
- IP Table Management
- Overlay definition between Nodes without using NAT (e.g. --pod-network-cidr management)
- Vxlan Interface implementation and etc.
- Network Management in the cluster:
- "An abstract way to expose an application running on a set of Pods as a network service.
- Kubernetes ServiceTypes allow you to specify what kind of Service you want. The default is ClusterIP.
- Type values and their behaviors are:
- ClusterIP: Exposes the Service on a cluster-internal IP. Choosing this value makes the Service only reachable from within the cluster. This is the default ServiceType.
- NodePort: Exposes the Service on each Node's IP at a static port (the NodePort). A ClusterIP Service, to which the NodePort Service routes, is automatically created. You'll be able to contact the NodePort Service, from outside the cluster, by requesting :.
- LoadBalancer: Exposes the Service externally using a cloud provider's load balancer. NodePort and ClusterIP Services, to which the external load balancer routes, are automatically created.
- ExternalName: Maps the Service to the contents of the externalName field (e.g. foo.bar.example.com), by returning a CNAME record with its value. No proxying of any kind is set up." (Ref: Kubernetes.io)
- Example of Service Object Definition: (Selector binds service to the related pods, get traffic from port 80 to port 9376)
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376Goto the Scenario: LAB: K8s Service Implementations (ClusterIp, NodePort and LoadBalancer)
- "The kubelet uses liveness probes to know when to restart a container. For example, liveness probes could catch a deadlock, where an application is running, but unable to make progress." (Ref: Kubernetes.io)
- There are different ways of controlling Pods:
- httpGet,
- exec command,
- tcpSocket,
- grpc, etc.
- initialDelaySeconds: waiting some period of time after starting. e.g. 5sec, after 5 sec start to run command
- periodSeconds: in a period of time, run command.
Goto the Scenario: LAB: K8s Liveness Probe
- "Sometimes, applications are temporarily unable to serve traffic. For example, an application might need to load large data or configuration files during startup, or depend on external services after startup. In such cases, you don't want to kill the application, but you don't want to send it requests either. Kubernetes provides readiness probes to detect and mitigate these situations. A pod with containers reporting that they are not ready does not receive traffic through Kubernetes Services." (Ref: Kubernetes.io)
- Readiness probe is similar to liveness pod. Only difference is to define "readinessProbe" instead of "livenessProbe".
- Pods can consume resources (cpu, memory) up to physical resource limits, if there was not any limitation.
- Pods' used resources can be limited.
- use 1 cpu core => cpu = "1" = "1000" = "1000m"
- use 10% of 1 cpu core => cpu = "0.1" = "100" = "100m"
- use 64 MB => memory: "64M"
- CPU resources are exactly limited when it defines.
- When pod requests memory resource more than limitation, pod changes its status to "OOMKilled" and restarts itself to limit memory usage.
- Example (below), pod requests 64MB memory and 0.25 CPU core, uses maximum 256MB memory and 0.5 CPU core.
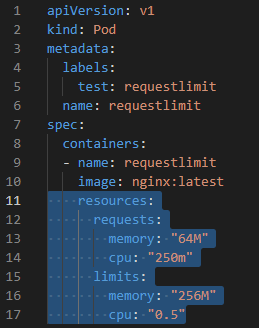
- Environment Variables can be defined for each pods in the YAML file.
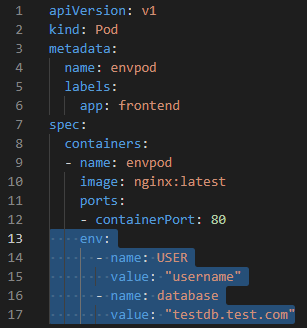
Goto the Scenario: LAB: K8s Creating Pod - Declarative Way - Environment Variable
- Ephemeral volume (Temporary volume): Multiple containers reach ephemeral volume in the pod. When the pod is deleted/killed, volume is also deleted. But when container is restarted, volume is still available because pod still runs.
- There are 2 types of ephemeral volumes:
- Emptydir
- Hostpath
- Directory
- DirectoryOrCreate
- FileOrCreate
- Emptydir (empty directory on the node) is created on which node the pod is created on and it is mounted on the container using "volumeMounts". Multiple containers in the pod can reach this volume (read/write).
- Emptydir volume is dependent of Pod Lifecycle. If the pod is deleted, emptydir is also deleted.
spec:
containers:
- name: sidecar
image: busybox
command: ["/bin/sh"]
args: ["-c", "sleep 3600"]
volumeMounts: # volume is mounted under "volumeMounts"
- name: cache-vol # "name" of the volume type
mountPath: /tmp/log # "mountPath" is the path in the container.
volumes:
- name: cache-vol
emptyDir: {} # "volume" type "emptydir"Goto the Scenario: LAB: K8s Multicontainer - Sidecar - Emptydir Volume - Port-Forwarding
- It is similar to emtpydir, hostpath is also created on which node the pod is created on. In addition, the hostpath is specifically defined path on the node.
apiVersion: v1
kind: Pod
metadata:
name: hostpath
spec:
containers:
- name: hostpathcontainer
image: ImageName # e.g. nginx
volumeMounts:
- name: directory-vol # container connects "volume" name
mountPath: /dir1 # on the container which path this volume is mounted
- name: dircreate-vol
mountPath: /cache # on the container which path this volume is mounted
- name: file-vol
mountPath: /cache/config.json # on the container which file this volume is mounted
volumes:
- name: directory-vol # "volume" name
hostPath: # "volume" type "hostpath"
path: /tmp # "path" on the node, "/tmp" is defined volume
type: Directory # "hostpath" type "Directory", existed directory
- name: dircreate-vol
hostPath: # "volume" type "hostpath"
path: /cache # "path" on the node
type: DirectoryOrCreate # "hostpath" type "DirectoryOrCreate", if it is not existed, create directory
- name: file-vol
hostPath: # "volume" type "hostpath"
path: /cache/config.json # "path" on the node
type: FileOrCreate # "hostpath" type "FileOrCreate", if it is not existed, create file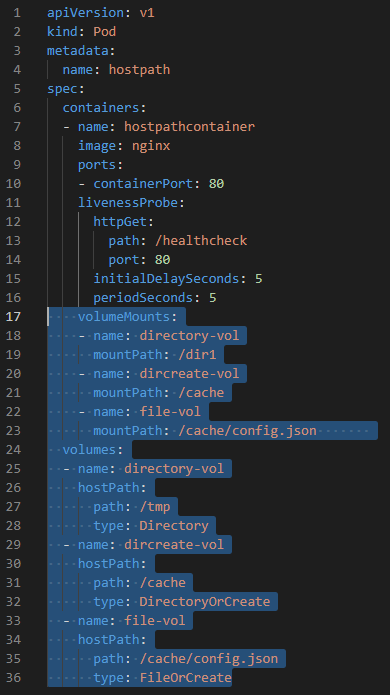
- Secret objects store the sensitive and secure information like username, password, ssh-tokens, certificates.
- Secrets (that you defined) and pods (that you defined) should be in the same namespace (e.g. if defined secret is in the "default" namespace, pod should be also in the "default" namepace).
- There are 8 different secret types (basic-auth, tls, ssh-auth, token, service-account-token, dockercfg, dockerconfigjson, opaque). Opaque type is the default one and mostly used.
- Secrets are called by the pod in 2 different ways: volume and environment variable
- Imperative way, run on the terminal (geneneric in the command = opaque):
kubectl create secret generic mysecret2 --from-literal=db_server=db.example.com --from-literal=db_username=admin --from-literal=db_password=P@ssw0rd!- Imperative way with file to hide pass in the command history
kubectl create secret generic mysecret3 --from-file=db_server=server.txt --from-file=db_username=username.txt --from-file=db_password=password.txt- Imperative way with json file to hide pass in the command history
kubectl create secret generic mysecret4 --from-file=config.jsonGoto the Scenario: LAB: K8s Secret (Declarative and Imperative Way)
- It is same as "secrets". The difference is that configmap does not save sensitive information. It stores config variables.
- Configmap stores data with key-value pairs.
- Configmaps are called by the pod in 2 different ways: volume and environment variable
- Scenario shows the usage of configmaps.
Goto the Scenario: LAB: K8s Config Map
- Affinity means closeness, proximity, familarity.
-
With node affinity, specific pods can enable to run on the desired node (Node selector also supports that feature, but node affinity is more flexible).
-
If node is labelled with key-value, we can run some of the pods on that specific node.
-
Terms for Node Affinity:
- requiredDuringSchedulingIgnoredDuringExecution: Find a node during scheduling according to "matchExpression" and run pod on that node. If it is not found, do not run this pod until finding specific node "matchExpression".
- IgnoredDuringExecution: After scheduling, if the node label is removed/deleted from node, ignore it while executing.
- preferredDuringSchedulingIgnoredDuringExecution: Find a node during scheduling according to "matchExpression" and run pod on that node. If it is not found, run this pod wherever it finds.
- weight: Preference weight. If weight is more than other weights, this weight is higher priority than others.
-
For a better understanding, please have a look LAB: K8s Node Affinity
Go to the Scenario: LAB: K8s Node Affinity
- Some of the pods should run with other pods on same node or same availability zone (e.g. frontend pods run with cache pod on the same availability zone)
- If pod affinity is defined for one pod, that pod runs with the related pod on same node or same availability zone.
- Each node in the cluster is labelled with default labels.
- "kubernetes.io/hostname": e.g "kubernetes.io/hostname=minikube"
- "kubernetes.io/arch": e.g "kubernetes.io/arch=amd64"
- "kubernetes.io/os": e.g "kubernetes.io/os=linux"
- Each node in the cluster that runs on the Cloud is labelled with following labels.
- "topology.kubernetes.io/region": e.g. "topology.kubernetes.io/region=northeurope"
- "topology.kubernetes.io/zone": e.g. "topology.kubernetes.io/zone=northeurope-1"
apiVersion: v1
kind: Pod
metadata:
name: frontendpod
labels:
app: frontend # defined labels
deployment: test
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
---
apiVersion: v1
kind: Pod
metadata:
name: cachepod
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # required: if not found, not run this pod on any node
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- frontend
topologyKey: kubernetes.io/hostname # run this pod with the POD which includes "app=frontend" on the same worker NODE
preferredDuringSchedulingIgnoredDuringExecution: # preferred: if not found, run this pod on any node
- weight: 1
podAffinityTerm:
labelSelector:
matchExpressions:
- key: branch
operator: In
values:
- develop
topologyKey: topology.kubernetes.io/zone # run this pod with the POD which includes "branch=develop" on the any NODE in the same ZONE
podAntiAffinity: # anti-affinity: NOT run this pod with the following match ""
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: deployment
operator: In
values:
- prod
topologyKey: topology.kubernetes.io/zone # NOT run this pod with the POD which includes "deployment=prod" on the any NODE in the same ZONE
containers:
- name: cachecontainer # cache image and container name
image: redis:6-alpine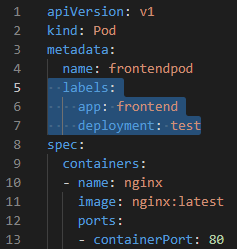

- Node affinity is a property of Pods that attracts/accepts them to a set of nodes. Taints are the opposite, they allow a node to repel/reject a set of pods.
- TAINTs are assigned to the NODEs. TOLERATIONs assigned to the PODs
- "kubectl describe nodes minikube", at taints section, it can be seen taints.
- To add taint to the node with commmand: "kubectl taint node minikube app=production:NoSchedule"
- To delete taint to the node with commmand: "kubectl taint node minikube app-"
- If pod has not any toleration for related taint, it can not be started on the tainted node (status of pod remains pending)
- Taint Types:
- key1=value1:effect: (e.g."kubectl taint node minikube app=production:NoSchedule")
- Taint "effect" types:
- NoSchedule: If pod is not tolerated with this effect, it can not run on the related node (status will be pending, until toleration/untaint)
- PreferNoSchedule: If pod is not tolerated with this effect and if there is not any untainted node, it can run on the related node.
- NoExecute: If pod is not tolerated with this effect, it can not run on the related node. If there are pods running on the node before assigning "NoExecute" taint, after tainting "NoExecute", untolerated pods stopped on this node.
- For clarification, please have a look LAB: K8s Taint Toleration
Goto the Scenario: LAB: K8s Taint-Toleration
- It provides to run pods on EACH nodes. It can be configured to run only specific nodes.
- For example, you can run log application that runs on each node in the cluster and app sends these logs to the main log server. Manual configuration of each nodes could be headache in this sceneario, so using deamon sets would be beneficial to save time and effort.
- If the new nodes are added on the cluster and running deamon sets on the cluster at that time period, default pods which are defined on deamon sets also run on the new nodes without any action.
Goto the scenario: LAB: K8s Daemonset - Creating 3 nodes on Minikube
- Volumes are ephemeral/temporary area that stores data. Emptydir and hostpath create volume on node which runs related pod.
- In the scenario of creating Mysql pod on cluster, we can not use emptydir and hostpath for long term. Because they don't provide the long term/persistent volume.
- Persistent volume provides long term storage area that runs out of the cluster.
- There are many storage solutions that can be enabled on the cluster: nfs, iscsi, azure disk, aws ebs, google pd, cephfs.
- Container Storage Interface (CSI) provides the connection of K8s cluster and different storage solution.
- "accessModes" types:
- "ReadWriteOnce": read/write for only 1 node.
- "ReadOnlyMany" : only read for many nodes.
- "ReadWriteMany": read/write for many nodes.
- "persistentVolumeReclaimPolicy" types: it defines the behaviour of volume after the end of using volume.
- "Retain" : volume remains with all data after using it.
- "Recycle": volume is not deleted but all data in the volume is deleted. We get empty volume if it is chosen.
- "Delete" : volume is deleted after using it.
# Creating Persistent Volume on NFS Server on the network
apiVersion: v1
kind: PersistentVolume
metadata:
name: mysqlpv
labels:
app: mysql # labelled PV with "mysql"
spec:
capacity:
storage: 5Gi # 5Gibibyte = power of 2; 5GB= power of 10
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle # volume is not deleted, all data in the volume will be deleted.
nfs:
path: /tmp # binds the path on the NFS Server
server: 10.255.255.10 # IP of NFS Server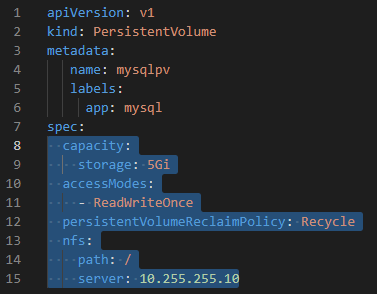
- We should create PVCs to use volume. With PVCs, existed PVs can be chosen.
- The reason why K8s manage volume with 2 files (PVC and PV) is to seperate the management of K8s Cluster (PV) and using of volume (PVC).
- If there is seperate role of system management of K8s cluster, system manager creates PV (to connect different storage vendors), developers only use existed PVs with PVCs.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysqlclaim
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem # VolumeMode
resources:
requests:
storage: 5Gi
storageClassName: ""
selector:
matchLabels:
app: mysql # choose/select "mysql" PV that is defined above.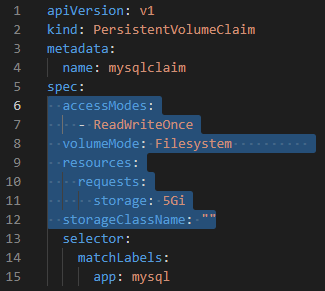
Goto the scenario: LAB: K8s Persistant Volume and Persistant Volume Claim
- Creating volume with PV is manual way of creating volume. With storage classes, it can be automated.
- Cloud providers provide storage classes on their infrastructure.
- When pod/deployment is created, storage class is triggered to create PV automatically (Trigger order: Pod -> PVC -> Storage Class -> PV).
# Storage Class Creation on Azure
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standarddisk
parameters:
cachingmode: ReadOnly
kind: Managed
storageaccounttype: StandardSSD_LRS
provisioner: kubernetes.io/azure-disk
reclaimPolicy: Delete
volumeBindingMode: WaitForFirstConsumer - "storageClassName" is added into PVC file.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysqlclaim
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 5Gi
storageClassName: "standarddisk" # selects/binds to storage class (defined above)- When deployment/pod request PVC (claim), storage class provides volume on the infrastructure automatically.
- Pods/Deployments are stateless objects. Stateful set provides to run stateful apps.
- Differences between Deployment and Statefulset:
- Name of the pods in the statefulset are not assigned randomly. It gives name statefulsetName_0,1,2,3.
- Pods in the statefulset are not created at the same time. Pods are created in order (new pod creation waits until previous pod's running status).
- When scaling down of statefulset, pods are not deleted in random. Pods are deleted in reverse order.
- If PVC is defined in the statefulset, each pod in the statefulset has own PV
Goto the scenario: LAB: K8s Stateful Sets - Nginx
- "A Job creates one or more Pods and will continue to retry execution of the Pods until a specified number of them successfully terminate". If the container is not successfully completed, it will recreated again.
- "When a specified number of successful completions is reached, the task (ie, Job) is complete."
- After finishing a job, pods are not deleted. Logs in the pods can be viewed.
- Job is used for the task that runs once (e.g. maintanence scripts, scripts that are used for creating DB)
- Job is also used for processing tasks that are stored in queue or bucket.
spec:
parallelism: 2 # each step how many pods start in parallel at a time
completions: 10 # number of pods that run and complete job at the end of the time
backoffLimit: 5 # to tolerate fail number of job, after 5 times of failure, not try to continue job, fail the job
activeDeadlineSeconds: 100 # if this job is not completed in 100 seconds, fail the job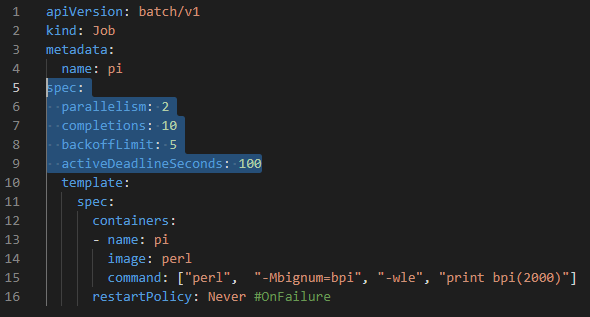
Goto the scenario: LAB: K8s Job
- Cron job is a scheduled job that can be started in scheduled time.
# ┌───────────── minute (0 - 59)
# │ ┌───────────── hour (0 - 23)
# │ │ ┌───────────── day of the month (1 - 31)
# │ │ │ ┌───────────── month (1 - 12)
# │ │ │ │ ┌───────────── day of the week (0 - 6) (Sunday to Saturday;
# │ │ │ │ │ 7 is also Sunday on some systems)
# │ │ │ │ │
# │ │ │ │ │
# * * * * *
#
# https://crontab.guru/
# Examples:
# 5 * * * * : (means) For every day start at minute 5: 00:05 - Second day 00:05 ....
# */5 * * * * : (means) At every 5th minute: 00:05 - 00:10 - 00:15 ...
# 0 */2 * * * : (means) At minute 0 pass every 2d hour: 00:00 - 02:00 - 04:00 ...
# "*" means "every"
# "/" means "repetitive"
spec:
schedule: "*/1 * * * *" # At every 1st minute: 00:01 - 00:02 ...
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
command: # start shell and echo
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure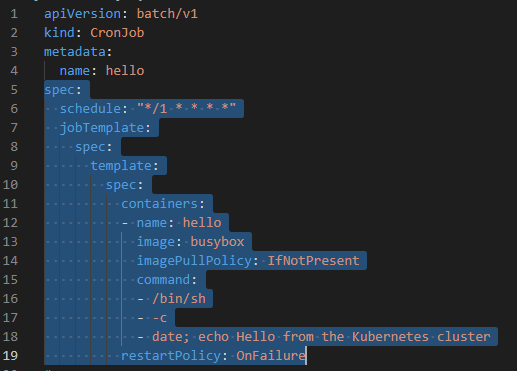
Go to the scenario: LAB: K8s Cron Job
- It is related to authenticate user to use specific cluster.
- Theory of the creating authentication is explained in short:
- user creates .key (key file) and .csr (certificate signing request file includes username and roles) with openssl application
- user sends .csr file to the K8s admin
- K8s admin creates a K8s object with this .csr file and creates .crt file (certification file) to give user
- user gets this .crt file (certification file) and creates credential (set-credentials) in user's pc with certification.
- user creates context (set-context) with cluster and credential, and uses this context.
- now it requires to get/create authorization for the user.
- It provides to give authorization (role) to the specific user.
- "Role", "RoleBinding" K8s objects are used to bind users for specific "namespace".
- "ClusterRole", "ClusterRoleBinding" K8s objects are used to bind users for specific "namespace".
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""] # "" indicates the core API group
resources: ["pods"] # "services", "endpoints", "pods", "pods/log" etc.
verbs: ["get", "watch", "list"] # "get", "list", "watch", "create", "update", "patch", "delete" 
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-pods
namespace: default
subjects:
- kind: User
name: [email protected] # "name" is case sensitive, this name was defined while creating .csr file
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role #this must be Role or ClusterRole
name: pod-reader # this must match the name of the Role or ClusterRole you wish to bind to
apiGroup: rbac.authorization.k8s.io 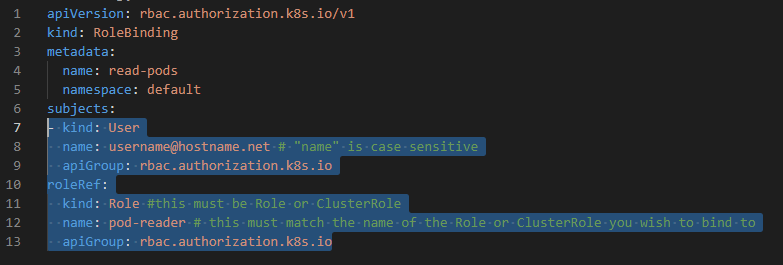
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: secret-reader
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get", "watch", "list"] 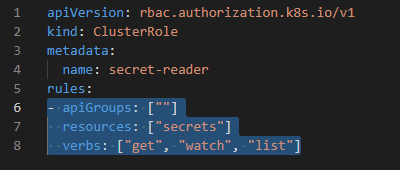
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: read-secrets-global
subjects:
- kind: Group
name: DevTeam # Name is case sensitive
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.io 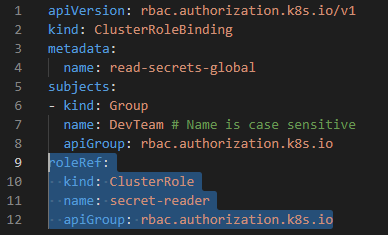
- RBACs are used for real people.
- Service accounts are used for pods/apps that can connect K8s API to create K8s objects.
- "An API object that manages external access to the services in a cluster, typically HTTP." (ref: Kubernetes.io)
- "Ingress may provide load balancing, SSL termination and name-based virtual hosting" (ref: Kubernetes.io)
- Ingress is not a Service type, but it acts as the entry point for your cluster.
- Ingress resource only supports rules for directing HTTP(S) (L7) traffic.
- "Ingress exposes HTTP and HTTPS routes from outside the cluster to services within the cluster. Traffic routing is controlled by rules defined on the Ingress resource." (ref: Kubernetes.io)
- Ingress controller is a L7 Application Loadbalancer that works in K8s according to K8s specification.
- Ingress Controllers: Nginx, HAproxy, Traefik
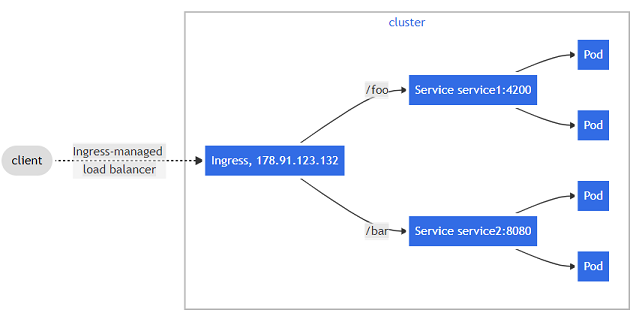 (ref: Kubernetes.io)
(ref: Kubernetes.io)
# Simple Ingress Object Definition
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: minimal-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx-example
rules:
- http:
paths:
- path: /testpath
pathType: Prefix
backend:
service:
name: test
port:
number: 80Goto the scenario: LAB: K8s Ingress
- You can view followings using default K8s dashboard:
- All Workloads on Cluster: Memory and CPU usages, update time, image name, node name, status
- Cron Jobs and Jobs
- Daeamon Sets
- Deployments, Replicasets
- Pods, Stateful Sets
- Services, Endpoints, IPs, Ports,
- Persistent Volume Claims, Persisten Volumes
- Config Maps,
- Secrets, Storage Classes
- Cluster Roles and Role Binding
- Namespaces
- Network Policies
- Nodes
- Roles and Role Bindings
- Service Accounts
# if working on minikube
minikube addons enable dashboard
minikube addons enable metrics-server
minikube dashboard
# if running on WSL/WSL2 to open browser
sensible-browser http://127.0.0.1:45771/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/
- to see better resolution, click on it
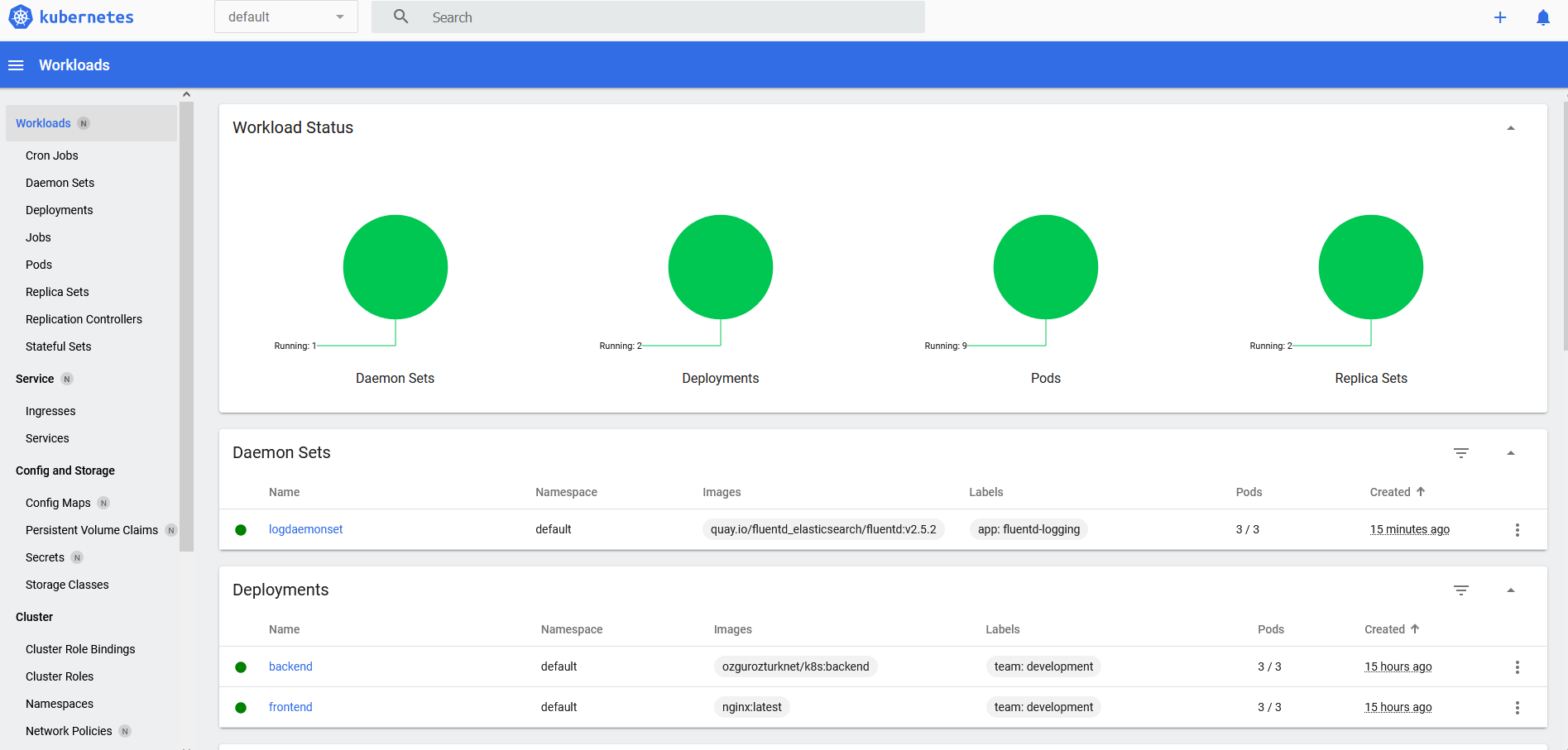
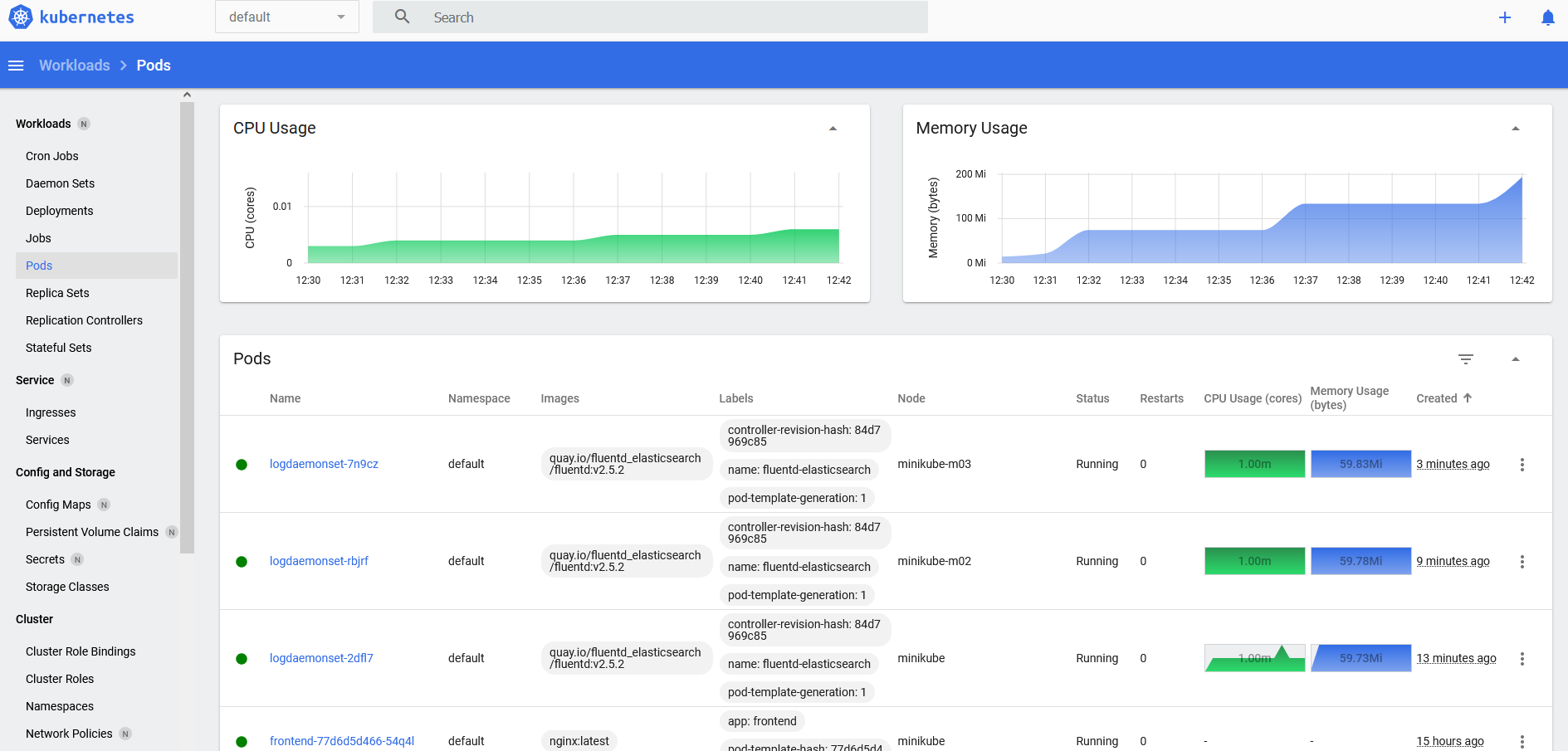
Goto the scenario: LAB: Enable Dashboard on Real Cluster
- Helm is the package manager of K8s (https://helm.sh/).
- "Helm installs charts into Kubernetes, creating a new release for each installation. And to find new charts, you can search Helm chart repositories." (Ref: Helm.sh)
- With Helm, it is easy to install best-practice K8s designs and products. Search K8s packages => https://artifacthub.io/
- Detailed Tutorial => https://helm.sh/docs/intro/quickstart/
- Important Terms: (Ref: Helm.sh)
- Chart: "A Chart is a Helm package. It contains all of the resource definitions necessary to run an application, tool, or service inside of a Kubernetes cluster. Think of it like the Kubernetes equivalent of a Homebrew formula, an Apt dpkg, or a Yum RPM file."
- Repository: "A Repository is the place where charts can be collected and shared"
- Release: "A Release is an instance of a chart running in a Kubernetes cluster. One chart can often be installed many times into the same cluster. And each time it is installed, a new release is created. Consider a MySQL chart. If you want two databases running in your cluster, you can install that chart twice. Each one will have its own release, which will in turn have its own release name."
Goto the scenario: LAB: HELM Install & Usage
Goto the scenario: LAB: Helm-Jenkins on running K8s Cluster (2 Node Multipass VM)
Goto: Helm Commands Cheatsheet
Goto: Kubernetes Commands Cheatsheet
Goto: Helm Commands Cheatsheet
Goto: LAB: K8s Kubeadm Cluster Setup
Goto: LAB: K8s Monitoring - Prometheus and Grafana
Goto: LAB: Enable Dashboard on Real K8s Cluster
- KubernetesTutorial
- Docker and Kubernetes Tutorial - Youtube: https://www.youtube.com/watch?v=bhBSlnQcq2k&t=3088s