Clojure data processing framework with parallel computing on larger-than-memory datasets
-
Unlimited Size
It supports datasets larger than memory.
-
Various Operations
Although Clojask is designed for larger-than-memory datasets, like NoSQLs, it does not sacrifice common operations on relational dataframes, such as group by, aggregate, join.
-
Fast
Faster than Dask in most operations, and the larger the dataframe is, the bigger the advantage. Please find the benchmarks here.
-
All Native Types
All the datatypes used to store data are native Clojure (or Java) types.
-
From File to File
Integrate IO inside the dataframe. No need to write your own read-in and output functions.
-
Parallel
Most operations could be executed into multiple threads or even machines. See the principle in Onyx.
-
Lazy Operations
Most operations will not be executed immediately. Dataframe will intelligently pipeline the operations altogether in computation.
-
Little Constraints on programming
Except for some aggregations where you need to write customized functions subject to simple templates, operations in Clojask support arbitrary Clojure functions as input
Available on Clojars 
Insert this line into your project.clj if using Leiningen.
[com.github.clojure-finance/clojask "2.0.2"]
Insert this line into your deps.edn if using CLI.
com.github.clojure-finance/clojask {:mvn/version "2.0.2"}Requirements:
- MacOS or Linux
- Java 8 - 11
-
Import
Clojask(require '[clojask.dataframe :as ck])
-
Initialize a dataframe
(def df (ck/dataframe "Employees-example.csv"))
The source file can be found here.
See
dataframe -
Preview the first few lines of the dataframe
(ck/print-df df)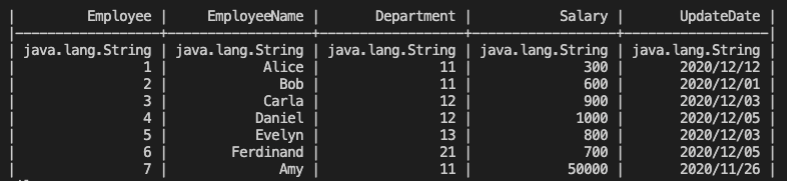
See
print-df -
Change the data type of some columns
(ck/set-type df "Salary" "double") (ck/set-type df "UpdateDate" "date:yyyy/MM/dd") (ck/print-df df)
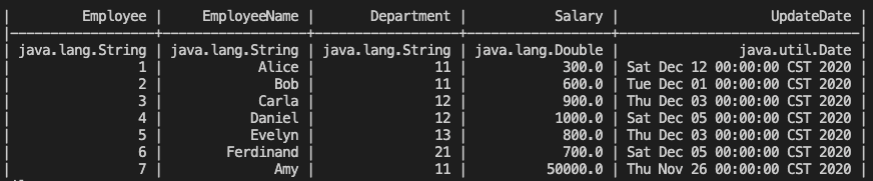
See
set-type -
Add 100 to Bob as
NewSalary(ck/operate df (fn [EmployeeName Salary] (if (= EmployeeName "Bob") (+ Salary 100) Salary)) ["EmployeeName" "Salary"] "NewSalary") (ck/print-df df)

See
operate -
Output the resultant dataset to "result.csv" (Use 8 threads)
(ck/compute df 8 "result.csv" :select ["Employee" "EmployeeName" "Department" "NewSalary" "UpdateDate"])
See
compute




- The solid arrows point to the fixed next step; dotted arrows point to all possible next steps.
- Any step except for Initialization is optional.
The detailed documentation for every API can be found here.
A separate repository for some typical usage of Clojask can be found here.
If your question is not answered in existing issues, feel free to create a new one.