Background: Outlier detection (OD) is a key data mining task for identifying abnormal objects from general samples with numerous high-stake applications including fraud detection and intrusion detection.
To scale outlier detection (OD) to large-scale, high-dimensional datasets, we propose TOD, a novel system that abstracts OD algorithms into basic tensor operations for efficient GPU acceleration.
The corresponding paper. The code is being cleaned up and released. Please watch and star!
On average, TOD is 11 times faster than PyOD!
If you need another reason: it can handle much larger datasets:more than a million sample OD within an hour!
TOD is featured for:
- Unified APIs, detailed documentation, and examples for the easy use (under construction)
- Supports more than 10 different OD algorithms and more are being added
- TOD supports multi-GPU acceleration
- Advanced techniques like provable quantization
kNN example shows that how fast and how easy PyTOD is. Take the famous kNN outlier detection as an example:
Initialize a kNN detector, fit the model, and make the prediction.
from pytod.models.knn import KNN # kNN detector # train kNN detector clf_name = 'KNN' clf = KNN() clf.fit(X_train)
# if GPU is not available, use CPU instead clf = KNN(device='cpu') clf.fit(X_train)
Get the prediction results
# get the prediction label and outlier scores of the training data y_train_pred = clf.labels_ # binary labels (0: inliers, 1: outliers) y_train_scores = clf.decision_scores_ # raw outlier scores
On a simple laptop, let us see how fast it is in comparison to PyOD for 30,000 samples with 20 features
KNN-PyOD ROC:1.0, precision @ rank n:1.0 Execution time 11.26 seconds
KNN-PyTOD-GPU ROC:1.0, precision @ rank n:1.0 Execution time 2.82 seconds
KNN-PyTOD-CPU ROC:1.0, precision @ rank n:1.0 Execution time 3.36 seconds
It is easy to see, PyTOD shows both better efficiency than PyOD.
Complex OD algorithms can be abstracted into common tensor operators.
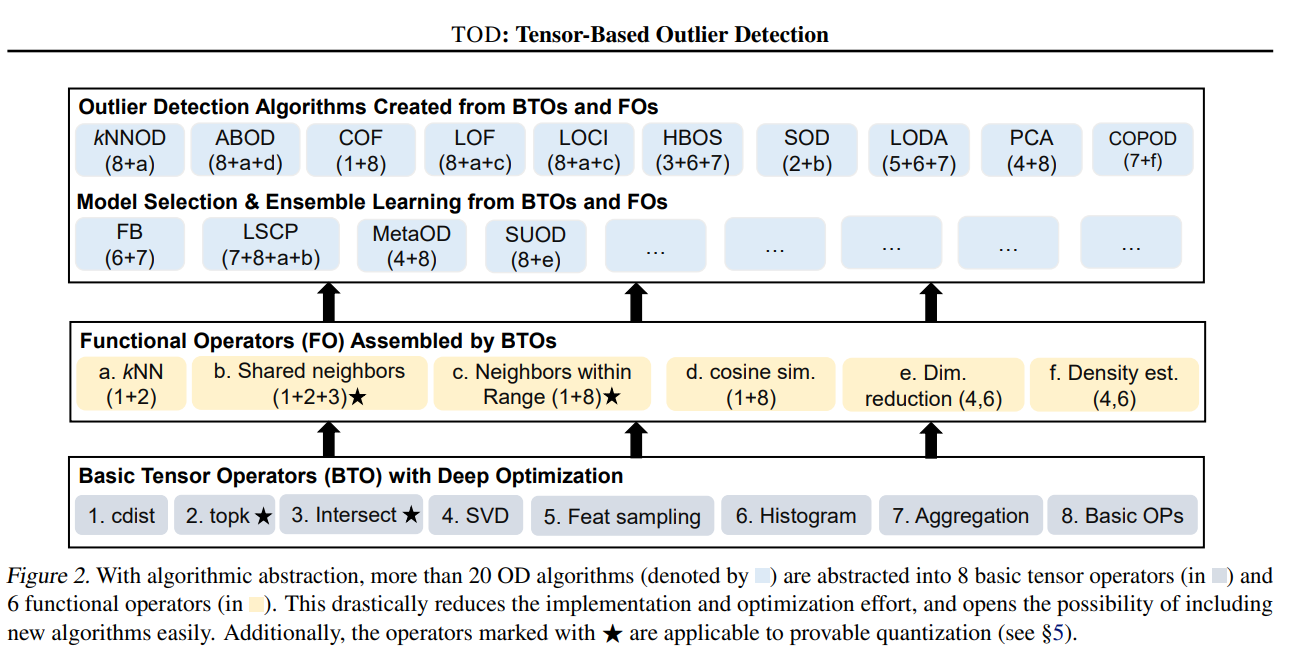
For instance, ABOD and COPOD can be assembled by the basic tensor operators.

Overall, it is much (on avg. 11 times) faster than PyOD takes way less run time.

PyTOD toolkit consists of three major functional groups (to be cleaned up):
(i) Individual Detection Algorithms :
| Type | Abbr | Algorithm | Year | Ref |
|---|---|---|---|---|
| Linear Model | PCA | Principal Component Analysis (the sum of weighted projected distances to the eigenvector hyperplanes) | 2003 | [#Shyu2003A]_ |
| Proximity-Based | LOF | Local Outlier Factor | 2000 | [#Breunig2000LOF]_ |
| Proximity-Based | COF | Connectivity-Based Outlier Factor | 2002 | [#Tang2002Enhancing]_ |
| Proximity-Based | HBOS | Histogram-based Outlier Score | 2012 | [#Goldstein2012Histogram]_ |
| Proximity-Based | kNN | k Nearest Neighbors (use the distance to the kth nearest neighbor as the outlier score) | 2000 | [#Ramaswamy2000Efficient]_ |
| Proximity-Based | AvgKNN | Average kNN (use the average distance to k nearest neighbors as the outlier score) | 2002 | [#Angiulli2002Fast]_ |
| Proximity-Based | MedKNN | Median kNN (use the median distance to k nearest neighbors as the outlier score) | 2002 | [#Angiulli2002Fast]_ |
| Probabilistic | ABOD | Angle-Based Outlier Detection | 2008 | [#Kriegel2008Angle]_ |
| Probabilistic | COPOD | COPOD: Copula-Based Outlier Detection | 2020 | [#Li2020COPOD]_ |
| Probabilistic | FastABOD | Fast Angle-Based Outlier Detection using approximation | 2008 | [#Kriegel2008Angle]_ |
Code is being released. Watch and star for the latest news!