Allosaurus (universal phone recognizer) extension for ELAN
- Download the latest version of ELAN from here and install it:
wget https://www.mpi.nl/tools/elan/ELAN-XX_linux.tar.gz
tar xzf ELAN-XX_linux.tar.gz
- Download a copy of this repo and unzip it. Copy the
allosaurus-elan-dev/folder into ELAN's extensions dir (ELAN-XX/lib/app/extensions/).
- If ELAN is not already installed on your Mac, download the latest .dmg installer and install it. It should be installed in the
/Applications/ELAN_XXdirectory, whereXXis the name of the version. - Download this zip file and unzip it. You should see a folder named
allosaurus-elan-devcontaining the contents of this repo. - Right-click
ELAN_XXand click "Show Package Contents", then copy yourallosaurus-elan-devfolder intoELAN_XX.app/Contents/app/extensions.
- Download the latest version of ELAN from here and install it.
- Download a copy of this repo and unzip it. Copy the
allosaurus-elan-dev/folder into ELAN's extensions dir (ELAN-XX/app/extensions/). - Install Python 3 if it isn't already installed.
Start ELAN with the provided test audio file
ELAN_6-1/bin/ELAN allosaurus-elan/test/allosaurus.wav &
Switch to the "Recognizers" tab and then select "Allosaurus Phoneme Recognizer" from the Recognizer dropdown list at the top and then click the "Start" button. If this is your first time using the allosaurus-elan plugin, you will be prompted to login to the CMULAB backend server and get an access token (you can create an account or simply login with an existing Google account):
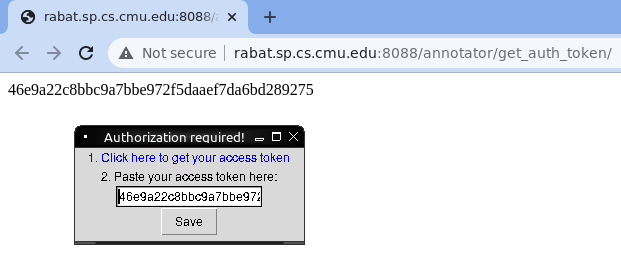
Once the plugin has finished processing the file, ELAN will prompt you to load the output tier generated by the recognizer. You should now be able to see the phoneme transcriptions in the timeline viewer.
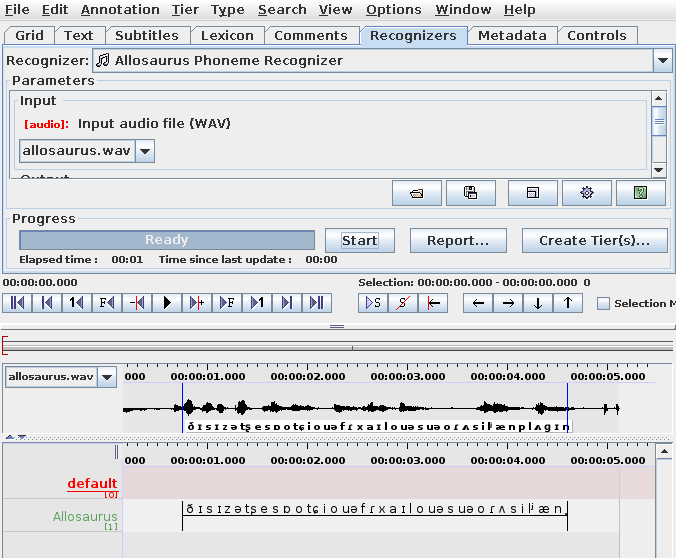
If the audio file is long, you can use an existing audio segmenter (for example, the "Fine audio segmentation" recognizer in ELAN) to segment the audio into utterance level segments first. Once that's done, before you run the "Allosaurus Phoneme Recognizer", in the "Parameters" section set the input tier to the audio segmenter output tier generated previously (for example: "Fine_Segmentation" tier).
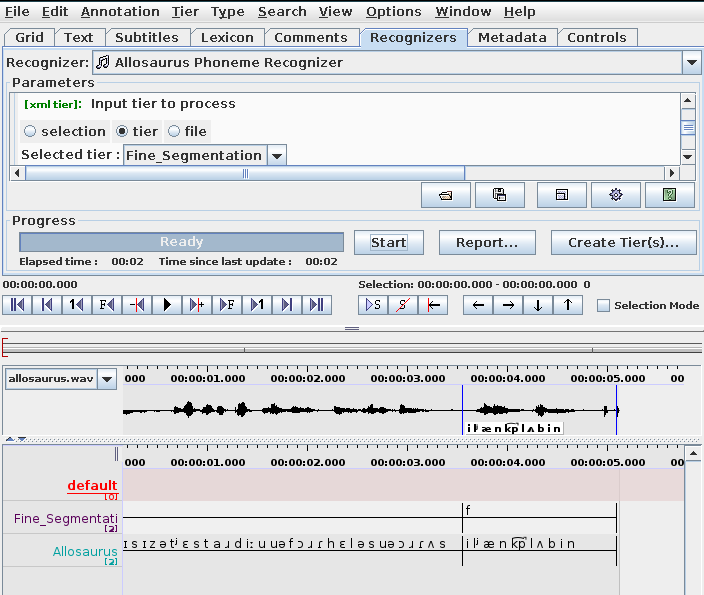
The plugin also supports uploading user-corrected phoneme transcriptions in order to fine-tune the pretrained models. After you run the plugin on any audio file, you can make corrections to the generated phoneme trasnscriptions and save it to an eaf file. To fine-tune allosaurus using these corrected transcriptions, open the parameters window and select the eaf file in the "Upload EAF file to fine-tune allosaurus" section:
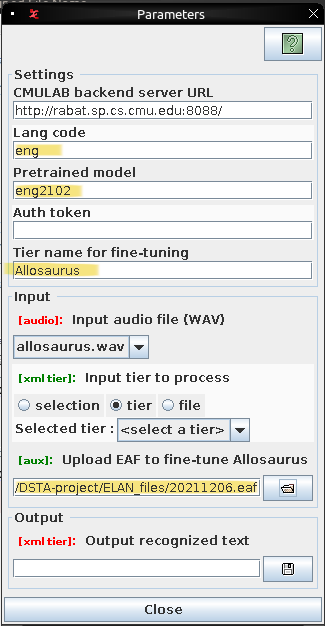
The fields relevant to fine-tuning are highlighted above. Make sure the name of the tier containing the user-corrected transcrptions matches that set in the "Tier name for fine-tuning" field. Currently due to some limitations, only fine-tuning of the "eng2102" pre-trained model is possible. Because the phonesets might differ between different models, it's best to fine-tune a model using transcriptions generated from the same model and lang code. Click on the "Report" button to get the ID of the new model (for example: eng2102_20211207001022575724). You can now use this model ID in the "Pretrained model" field (Parameters section) and re-run allosaurus-elan to check if the output from the new model is better.
Note: In order to transcribe audio using the new model ID, make sure the "Upload EAF file to fine-tune allosaurus" field has been cleared, otherwise the plugin will run again in "fine-tuning" mode.