By Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
Microsoft Research Asia (MSRA).
This repository contains the original models (ResNet-50, ResNet-101, and ResNet-152) described in the paper "Deep Residual Learning for Image Recognition" (http://arxiv.org/abs/1512.03385). These models are those used in [ILSVRC] (http://image-net.org/challenges/LSVRC/2015/) and COCO 2015 competitions, which won the 1st places in: ImageNet classification, ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
Note - Check re-implementations with training code and models from Facebook AI Research (FAIR)! -- blog, code
If you use these models in your research, please cite:
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
- These models are converted from our own implementation to a recent version of Caffe (2016/2/3, b590f1d). The numerical results using this code are as in the tables below.
- These models are for the usage of testing or fine-tuning.
- These models were not trained using this version of Caffe.
- If you want to train these models using this version of Caffe without modifications, please notice that:
- GPU memory might be insufficient for extremely deep models.
- Changes of mini-batch size should impact accuracy (we use a mini-batch of 256 images on 8 GPUs, that is, 32 images per GPU).
- Implementation of data augmentation might be different (see our paper about the data augmentation we used).
- We randomly shuffle data at the beginning of every epoch.
- There might be some other untested issues.
- In our BN layers, the provided mean and variance are strictly computed using average (not moving average) on a sufficiently large training batch after the training procedure. The numerical results are very stable (variation of val error < 0.1%). Using moving average might lead to different results.
- In the BN paper, the BN layer learns gamma/beta. To implement BN in this version of Caffe, we use its provided "batch_norm_layer" (which has no gamma/beta learned) followed by "scale_layer" (which learns gamma/beta).
- We use Caffe's implementation of SGD with momentum: v := momentum*v + lr*g. If you want to port these models to other libraries (e.g., Torch, CNTK), please pay careful attention to the possibly different implementation of SGD with momentum: v := momentum*v + (1-momentum)*lr*g, which changes the effective learning rates.
-
Visualizations of network structures (tools from ethereon):
- [ResNet-50] (http://ethereon.github.io/netscope/#/gist/db945b393d40bfa26006)
- [ResNet-101] (http://ethereon.github.io/netscope/#/gist/b21e2aae116dc1ac7b50)
- [ResNet-152] (http://ethereon.github.io/netscope/#/gist/d38f3e6091952b45198b)
-
Model files:
- MSR download: [link] (http://research.microsoft.com/en-us/um/people/kahe/resnet/models.zip)
- OneDrive download: link
-
Curves on ImageNet (solid lines: 1-crop val error; dashed lines: training error):
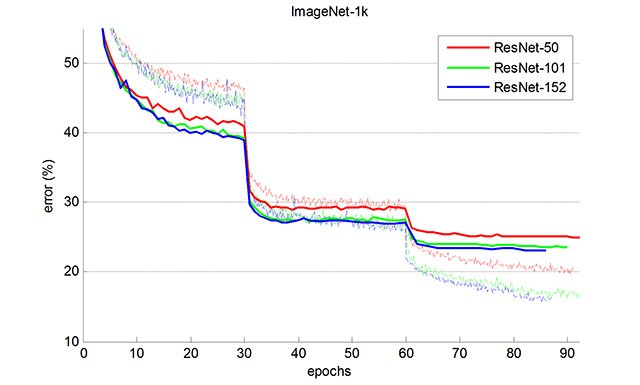
-
1-crop validation error on ImageNet (center 224x224 crop from resized image with shorter side=256):
model top-1 top-5 VGG-16 28.5% 9.9% ResNet-50 24.7% 7.8% ResNet-101 23.6% 7.1% ResNet-152 23.0% 6.7% -
10-crop validation error on ImageNet (averaging softmax scores of 10 224x224 crops from resized image with shorter side=256), the same as those in the paper:
model top-1 top-5 ResNet-50 22.9% 6.7% ResNet-101 21.8% 6.1% ResNet-152 21.4% 5.7%
Deep residual networks are very easy to implement and train. We recommend to see also the following third-party re-implementations and extensions:
- By Facebook AI Research (FAIR), with training code in Torch and pre-trained ResNet-18/34/50/101 models for ImageNet: blog, code
- Torch, CIFAR-10, with ResNet-20 to ResNet-110, training code, and curves: code
- Lasagne, CIFAR-10, with ResNet-32 and ResNet-56 and training code: code
- Neon, CIFAR-10, with pre-trained ResNet-32 to ResNet-110 models, training code, and curves: code
- Torch, MNIST, 100 layers: blog, code
- A winning entry in Kaggle's right whale recognition challenge: blog, code
- Neon, Place2 (mini), 40 layers: blog, code
In addition, this [code] (https://github.com/ry/tensorflow-resnet) by Ryan Dahl helps to convert the pre-trained models to TensorFlow.